
Experimental design and pattern estimation#
This week’s lab will be about the basics of pattern analysis of (f)MRI data. We assume that you’ve worked through the two Nilearn tutorials already.
Functional MRI data are most often stored as 4D data, with 3 spatial dimensions (\(X\), \(Y\), and \(Z\)) and 1 temporal dimension (\(T\)). But most pattern analyses assume that data are formatted in 2D: trials (\(N\)) by patterns (often a subset of \(X\), \(Y\), and \(Z\)). Where did the time dimension (\(T\)) go? And how do we “extract” the patterns of the \(N\) trials? In this lab, we’ll take a look at various methods to estimate patterns from fMRI time series. Because these methods often depend on your experimental design (and your research question, of course), the first part of this lab will discuss some experimental design considerations. After this more theoretical part, we’ll dive into how to estimate patterns from fMRI data.
What you’ll learn: At the end of this tutorial, you …
Understand the most important experimental design factors for pattern analyses;
Understand and are able to implement different pattern estimation techniques
Estimated time needed to complete: 8-12 hours
# We need to limit the amount of threads numpy can use, otherwise
# it tends to hog all the CPUs available when using Nilearn
import os
os.environ['MKL_NUM_THREADS'] = '1'
os.environ['OPENBLAS_NUM_THREADS'] = '1'
import numpy as np
Experimental design#
Before you can do any fancy machine learning or representational similarity analysis (or any other pattern analysis), there are several decisions you need to make and steps to take in terms of study design, (pre)processing, and structuring your data. Roughly, there are three steps to take:
Design your study in a way that’s appropriate to answer your question through a pattern analysis; this, of course, needs to be done before data acquisition!
Estimate/extract your patterns from the (functional) MRI data;
Structure and preprocess your data appropriately for pattern analyses;
While we won’t go into all the design factors that make for an efficient pattern analysis (see this article for a good review), we will now discuss/demonstrate some design considerations and how they impact the rest of the MVPA pipeline.
Within-subject vs. between-subject analyses#
As always, your experimental design depends on your specific research question. If, for example, you’re trying to predict schizophrenia patients from healthy controls based on structural MRI, your experimental design is going to be different than when you, for example, are comparing fMRI activity patterns in the amygdala between trials targeted to induce different emotions. Crucially, with design we mean the factors that you as a researcher control: e.g., which schizophrenia patients and healthy control to scan in the former example and which emotion trials to present at what time. These two examples indicate that experimental design considerations are quite different when you are trying to model a factor that varies between subjects (the schizophrenia vs. healthy control example) versus a factor that varies within subjects (the emotion trials example).
- https://www.nature.com/articles/nn1444 (machine learning based)
- http://www.jneurosci.org/content/33/47/18597.short (RSA based)
- https://www.sciencedirect.com/science/article/pii/S1053811913000074 (machine learning based)
Assign either ‘within’ or ‘between’ to the variables corresponding to the studies above (i.e., study_1, study_2, study_3).
''' Implement the ToDo here. '''
study_1 = '' # fill in 'within' or 'between'
study_2 = '' # fill in 'within' or 'between'
study_3 = '' # fill in 'within' or 'between'
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
for this_study in [study_1, study_2, study_3]:
if not this_study: # if empty string
raise ValueError("You haven't filled in anything!")
else:
if this_study not in ['within', 'between']:
raise ValueError("Fill in either 'within' or 'between'!")
print("Your answer will be graded by hidden tests.")
Note that, while we think it is a useful way to think about different types of studies, it is possible to use “hybrid” designs and analyses. For example, you could compare patterns from a particular condition (within-subject) across different participants (between-subject). This is, to our knowledge, not very common though, so we won’t discuss it here.
Suppose a researcher wants to implement a decoding analysis in which he/she aims to predict schizophrenia (vs. healthy control) from gray-matter density patterns in the orbitofrontal cortex. Is this an example of a within-subject or between-subject pattern analysis? Can it be either one? Why (not)?
YOUR ANSWER HERE
That said, let’s talk about something that is not only important for univariate MRI analyses, but also for pattern-based multivariate MRI analyses: confounds.
Confounds#
For most task-based MRI analyses, we try to relate features from our experiment (stimuli, responses, participant characteristics; let’s call these \(\mathbf{S}\)) to brain features (this is not restricted to “activity patterns”; let’s call these \(\mathbf{R}\)*). Ideally, we have designed our experiment that any association between our experimental factor of interest (\(\mathbf{S}\)) and brain data (\(\mathbf{R}\)) can only be due to our experimental factor, not something else.
If another factor besides our experimental factor of interest can explain this association, this “other factor” may be a confound (let’s call this \(\mathbf{C}\)). If we care to conclude anything about our experimental factor of interest and its relation to our brain data, we should try to minimize any confounding factors in our design.
* Note that the notation for experimental variables (\(\mathbf{S}\)) and brain features (\(\mathbf{R}\)) is different from what we used in the previous course, in which we used \(\mathbf{X}\) for experimental variables and \(\mathbf{y}\) for brain signals. We did this to conform to the convention to use \(\mathbf{X}\) for the set of independent variables and \(\mathbf{y}\) for dependent variables. In some pattern analyses (such as RSA), however, this independent/dependent variable distintion does not really apply, so that’s why we’ll stick to the more generic \(\mathbf{R}\) (for brain features) and \(\mathbf{S}\) (for experimental features) terms.
Statistically speaking, you should design your experiment in such a way that there are no associations (correlations) between \(\mathbf{R}\) and \(\mathbf{C}\), such that any association between \(\mathbf{S}\) and \(\mathbf{R}\) can only be due to \(\mathbf{R}\). Note that this is not trivial, because this presumes that you (1) know which factors might confound your study and (2) if you know these factors, that they are measured properly (Westfall & Yarkoni, 2016)).
Minimizing confounds in between-subject studies is notably harder than in within-subject designs, especially when dealing with clinical populations that are hard to acquire, because it is simply easier to experimentally control within-subject factors (especially when they are stimulus- rather than response-based). There are ways to deal with confounds post-hoc, but ideally you prevent confounds in the first place. For an overview of confounds in (multivariate/decoding) neuroimaging analyses and a proposed post-hoc correction method, see this article (apologies for the shameless self-promotion) and this follow-up article.
In sum, as with any (neuroimaging) analysis, a good experimental design is one that minimizes the possibilities of confounds, i.e., associations between factors that are not of interest (\(\mathbf{C}\)) and experimental factors that are of interest (\(\mathbf{S}\)).
YOUR ANSWER HERE
What makes up a “pattern”?#
So far, we talked a lot about “patterns”, but what do we mean with that term? There are different options with regard to what you choose as your unit of measurement that makes up your pattern. The far majority of pattern analyses in functional MRI use patterns of activity estimates, i.e., the same unit of measurement — relative (de)activation — as is common in standard mass-univariate analyses. For example, decoding object category (e.g., images of faces vs. images of houses) from fMRI activity patterns in inferotemporal cortex is an example of a pattern analysis that uses activity estimates as its unit of measurement.
However, you are definitely not limited to using activity estimates for your patterns. For example, you could apply pattern analyses to structural data (e.g., patterns of voxelwise gray-matter volume values, like in voxel-based morphometry) or to functional connectivity data (e.g., patterns of time series correlations between voxels, or even topological properties of brain networks). (In fact, the connectivity examples from the Nilearn tutorial represents a way to estimate these connectivity features, which can be used in pattern analyses.) In short, pattern analyses can be applied to patterns composed of any type of measurement or metric!
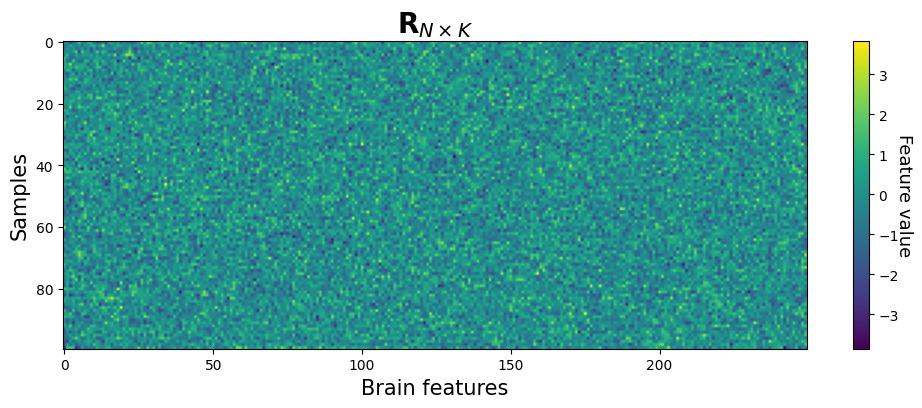
Now, let’s get a little more technical. Usually, as mentioned in the beginning, pattern analyses represent the data as a 2D array of brain patterns. Let’s call this \(\mathbf{R}\). The rows of \(\mathbf{R}\) represent different instances of patterns (sometimes called “samples” or “observations”) and the columns represent different brain features (e.g., voxels; sometimes simply called “features”). Note that we thus lose all spatial information by “flattening” our patterns into 1D rows!
Let’s call the number of samples \(N\) and the number of brain features \(K\). We can thus represent \(\mathbf{R}\) as a \(N\times K\) matrix (2D array):
As discussed before, the values themselves (e.g., \(R_{1,1}\), \(R_{1,2}\), \(R_{3,6}\)) represent whatever you chose for your patterns (fMRI activity, connectivity estimates, VBM, etc.). What is represented by the rows (samples/observations) of \(\mathbf{R}\) depends on your study design: in between-subject studies, these are usually participants, while in within-subject studies, these samples represent trials (or averages of trials or sometimes runs). The columns of \(\mathbf{R}\) represent the different (brain) features in your pattern; for example, these may be different voxels (or sensors/magnetometers in EEG/MEG), vertices (when working with cortical surfaces), edges in functional brain networks, etc. etc.
Let’s make it a little bit more concrete. We’ll make up some random data below that represents a typical data array in pattern analyses:
import numpy as np
N = 100 # e.g. trials
K = 250 # e.g. voxels
R = np.random.normal(0, 1, size=(N, K))
R
array([[ 0.00890593, -0.31802499, -2.142283 , ..., 1.12134571,
0.01308994, -1.00343244],
[-1.07670487, -0.65934883, 0.81664699, ..., -1.32881353,
0.84832687, -0.36449628],
[-0.72084621, 0.41802311, -0.39306505, ..., -0.06215944,
2.10336356, -0.71995603],
...,
[-1.85575468, -2.47842589, 0.45494257, ..., 0.29982543,
1.69296197, 0.85480972],
[-2.2691001 , 1.06158089, -1.12249596, ..., 0.25613703,
-0.44379499, 1.7956331 ],
[-3.03170391, 1.43755225, 1.49718243, ..., -2.22951371,
-0.17474734, -0.68560744]])
Let’s visualize this:
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.imshow(R, aspect='auto')
plt.xlabel('Brain features', fontsize=15)
plt.ylabel('Samples', fontsize=15)
plt.title(r'$\mathbf{R}_{N\times K}$', fontsize=20)
cbar = plt.colorbar()
cbar.set_label('Feature value', fontsize=13, rotation=270, labelpad=10)
plt.show()
''' Implement the ToDo here.'''
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_R_indexing
test_R_indexing(R, trial42, feat187, t60_f221)
Alright, to practice a little bit more. We included whole-brain VBM data for 20 subjects in the vbm/ subfolder:
import os
sorted(os.listdir('vbm'))
['sub-01.nii.gz',
'sub-02.nii.gz',
'sub-03.nii.gz',
'sub-04.nii.gz',
'sub-05.nii.gz',
'sub-06.nii.gz',
'sub-07.nii.gz',
'sub-08.nii.gz',
'sub-09.nii.gz',
'sub-10.nii.gz',
'sub-11.nii.gz',
'sub-12.nii.gz',
'sub-13.nii.gz',
'sub-14.nii.gz',
'sub-15.nii.gz',
'sub-16.nii.gz',
'sub-17.nii.gz',
'sub-18.nii.gz',
'sub-19.nii.gz',
'sub-20.nii.gz']
The VBM data represents spatially normalized (to MNI152, 2mm), whole-brain voxelwise gray matter volume estimates (read more about VBM here).
Let’s inspect the data from a single subject:
import os
import nibabel as nib
from nilearn import plotting
sub_01_vbm_path = os.path.join('vbm', 'sub-01.nii.gz')
sub_01_vbm = nib.load(sub_01_vbm_path)
print("Shape of Nifti file: ", sub_01_vbm.shape)
# Let's plot it as well
plotting.plot_anat(sub_01_vbm)
plt.show()
Shape of Nifti file: (91, 109, 91)
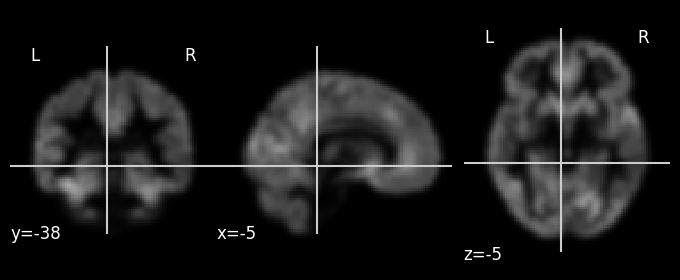
As you can see, the VBM data is a 3D array of shape 91 (\(X\)) \(\times\) 109 (\(Y\)) \(\times\) 91 (\(Z\)) (representing voxels). These are the spatial dimensions associated with the standard MNI152 (2 mm) template provided by FSL. As VBM is structural (not functional!) data, there is no time dimension (\(T\)).
Now, suppose that we want to do a pattern analysis on the data of all 20 subjects. We should then create a 2D array of shape 20 (subjects) \(\times\ K\) (number of voxels, i.e., \(91 \times 109 \times 91\)). To do so, we need to create a loop over all files, load them in, “flatten” the data, and ultimately stack them into a 2D array.
Before you’ll implement this as part of the next ToDo, we will show you a neat Python function called glob, which allows you to simply find files using “wildcards”:
from glob import glob
It works as follows:
list_of_files = glob('path/with/subdirectories/*/*.nii.gz')
Importantly, the string you pass to glob can contain one or more wildcard characters (such as ? or *). Also, the returned list is not sorted! Let’s try to get all our VBM subject data into a list using this function:
# Let's define a "search string"; we'll use the os.path.join function
# to make sure this works both on Linux/Mac and Windows
search_str = os.path.join('vbm', 'sub-*.nii.gz')
vbm_files = glob(search_str)
# this is also possible: vbm_files = glob(os.path.join('vbm', 'sub-*.nii.gz'))
# Let's print the returned list
print(vbm_files)
['vbm/sub-06.nii.gz', 'vbm/sub-01.nii.gz', 'vbm/sub-12.nii.gz', 'vbm/sub-17.nii.gz', 'vbm/sub-02.nii.gz', 'vbm/sub-15.nii.gz', 'vbm/sub-13.nii.gz', 'vbm/sub-19.nii.gz', 'vbm/sub-20.nii.gz', 'vbm/sub-18.nii.gz', 'vbm/sub-04.nii.gz', 'vbm/sub-16.nii.gz', 'vbm/sub-08.nii.gz', 'vbm/sub-07.nii.gz', 'vbm/sub-05.nii.gz', 'vbm/sub-14.nii.gz', 'vbm/sub-09.nii.gz', 'vbm/sub-03.nii.gz', 'vbm/sub-10.nii.gz', 'vbm/sub-11.nii.gz']
As you can see, the list is not alphabetically sorted, so let’s fix that with the sorted function:
vbm_files = sorted(vbm_files)
print(vbm_files)
# Note that we could have done that with a single statement
# vbm_files = sorted(glob(os.path.join('vbm', 'sub-*.nii.gz')))
# But also remember: shorter code is not always better!
['vbm/sub-01.nii.gz', 'vbm/sub-02.nii.gz', 'vbm/sub-03.nii.gz', 'vbm/sub-04.nii.gz', 'vbm/sub-05.nii.gz', 'vbm/sub-06.nii.gz', 'vbm/sub-07.nii.gz', 'vbm/sub-08.nii.gz', 'vbm/sub-09.nii.gz', 'vbm/sub-10.nii.gz', 'vbm/sub-11.nii.gz', 'vbm/sub-12.nii.gz', 'vbm/sub-13.nii.gz', 'vbm/sub-14.nii.gz', 'vbm/sub-15.nii.gz', 'vbm/sub-16.nii.gz', 'vbm/sub-17.nii.gz', 'vbm/sub-18.nii.gz', 'vbm/sub-19.nii.gz', 'vbm/sub-20.nii.gz']
''' Implement the ToDo here. '''
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_R_vbm_loop
test_R_vbm_loop(R_vbm)
# Run this cell after you're done with the ToDo
# This will remove the all numpy arrays from memory,
# clearing up RAM for the next sections
%reset -f array
Patterns as “points in space”#
Before we continue with the topic of pattern estimation, there is one idea that we’d like to introduce: thinking of patterns as points (i.e., coordinates) in space. Thinking of patterns this way is helpful to understanding both machine learning based analyses and representational similarity analysis. While for some, this idea might sound trivial, we believe it’s worth going over anyway. Now, let’s make this idea more concrete.
Suppose we have estimated fMRI activity patterns for 20 trials (rows of \(\mathbf{R}\)). Now, we will also assume that those patterns consist of only two features (e.g., voxels; columns of \(\mathbf{R}\)), because this will make visualizing patterns as points in space easier than when we choose a larger number of features.
Alright, let’s simulate and visualize the data (as a 2D array):
K = 2 # features (voxels)
N = 20 # samples (trials)
R = np.random.multivariate_normal(np.zeros(K), np.eye(K), size=N)
print("Shape of R:", R.shape)
# Plot 2D array as heatmap
fig, ax = plt.subplots(figsize=(2, 10))
mapp = ax.imshow(R)
cbar = fig.colorbar(mapp, pad=0.1)
cbar.set_label('Feature value', fontsize=13, rotation=270, labelpad=15)
ax.set_yticks(np.arange(N))
ax.set_xticks(np.arange(K))
ax.set_title(r"$\mathbf{R}$", fontsize=20)
ax.set_xlabel('Voxels', fontsize=15)
ax.set_ylabel('Trials', fontsize=15)
plt.show()
Shape of R: (20, 2)
Now, we mentioned that each pattern (row of \(\mathbf{R}\), i.e., \(\mathbf{R}_{i}\)) can be interpreted as a point in 2D space. With space, here, we mean a space where each feature (e.g., voxel; column of \(\mathbf{R}\), i.e., \(\mathbf{R}_{j}\)) represents a separate axis. In our simulated data, we have two features (e.g., voxel 1 and voxel 2), so our space will have two axes:
plt.figure(figsize=(5, 5))
plt.title("A two-dimensional space", fontsize=15)
plt.grid()
plt.xlim(-3, 3)
plt.ylim(-3, 3)
plt.xlabel('Activity voxel 1', fontsize=13)
plt.ylabel('Activity voxel 2', fontsize=13)
plt.show()
Within this space, each of our patterns (samples) represents a point. The values of each pattern represent the coordinates of its location in this space. For example, the coordinates of the first pattern are:
print(R[0, :])
[-0.06310333 0.3749162 ]
As such, we can plot this pattern as a point in space:
plt.figure(figsize=(5, 5))
plt.title("A two-dimensional space", fontsize=15)
plt.grid()
# We use the "scatter" function to plot this point, but
# we could also have used plt.plot(R[0, 0], R[0, 1], marker='o')
plt.scatter(R[0, 0], R[0, 1], marker='o', s=75)
plt.axhline(0, c='k')
plt.axvline(0, c='k')
plt.xlabel('Activity voxel 1', fontsize=13)
plt.ylabel('Activity voxel 2', fontsize=13)
plt.xlim(-3, 3)
plt.ylim(-3, 3)
plt.show()
If we do this for all patterns, we get an ordinary scatter plot of the data:
plt.figure(figsize=(5, 5))
plt.title("A two-dimensional space", fontsize=15)
plt.grid()
# We use the "scatter" function to plot this point, but
# we could also have used plt.plot(R[0, 0], R[0, 1], marker='o')
plt.axhline(0, c='k')
plt.axvline(0, c='k')
plt.scatter(R[:, 0], R[:, 1], marker='o', s=75, zorder=3)
plt.xlabel('Activity voxel 1', fontsize=13)
plt.ylabel('Activity voxel 2', fontsize=13)
plt.xlim(-3, 3)
plt.ylim(-3, 3)
plt.show()
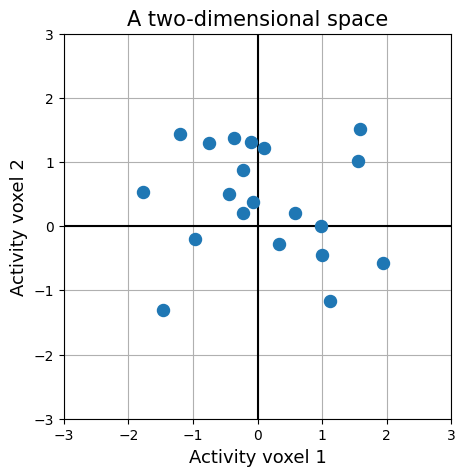
It is important to realize that both perspectives — as a 2D array and as a set of points in \(K\)-dimensional space — represents the same data! Practically, pattern analysis algorithms usually expect the data as a 2D array, but (in our experience) the operations and mechanisms implemented by those algorithms are easiest to explain and to understand from the “points in space” perspective.
You might think, “but how does this work for data with more than two features?” Well, the idea of patterns as points in space remains the same: each feature represents a new dimension (or “axis”). For three features, this means that a pattern represents a point in 3D (X, Y, Z) space; for four features, a pattern represents a point in 4D space (like a point moving in 3D space) … but what about a pattern with 14 features? Or 500? Actually, this is impossible to visualize or even make sense of mentally. As the famous artificial intelligence researcher Geoffrey Hinton put it:
“To deal with … a 14 dimensional space, visualize a 3D space and say ‘fourteen’ very loudly. Everyone does it.” (Geoffrey Hinton)
The important thing to understand, though, is that most operations, computations, and algorithms that deal with patterns do not care about whether your data is 2D (two features) or 14D (fourteen features) — we just have to trust the mathematicians that whatever we do on 2D data will generalize to \(K\)-dimensional data :-)
That said, people still try to visualize >2D data using dimensionality reduction techniques. These techniques try to project data to a lower-dimensional space. For example, you can transform a dataset with 500 features (i.e., a 500-dimensional dataset) to a 2D dimensional dataset using techniques such as principal component analysis (PCA), Multidimensional Scaling (MDS), and t-SNE. For example, PCA tries to a subset of uncorrelated lower-dimensional features (e.g., 2) from linear combinations of high-dimensional features (e.g., 4) that still represent as much variance of the high-dimensional components as possible. We’ll show you an example below using an implementation of PCA from the machine learning library scikit-learn, which we’ll use extensively in next week’s lab:
from sklearn.decomposition import PCA
# Let's create a dataset with 100 samples and 4 features
R4D = np.random.normal(0, 1, size=(100, 4))
print("Shape R4D:", R4D.shape)
# We'll instantiate a PCA object that will
# transform our data into 2 components
pca = PCA(n_components=2)
# Fit and transform the data from 4D to 2D
R2D = pca.fit_transform(R4D)
print("Shape R2D:", R2D.shape)
# Plot the result
plt.figure(figsize=(5, 5))
plt.scatter(R2D[:, 0], R2D[:, 1], marker='o', s=75, zorder=3)
plt.axhline(0, c='k')
plt.axvline(0, c='k')
plt.xlabel('PCA component 1', fontsize=13)
plt.ylabel('PCA component 2', fontsize=13)
plt.grid()
plt.xlim(-4, 4)
plt.ylim(-4, 4)
plt.show()
Shape R4D: (100, 4)
Shape R2D: (100, 2)
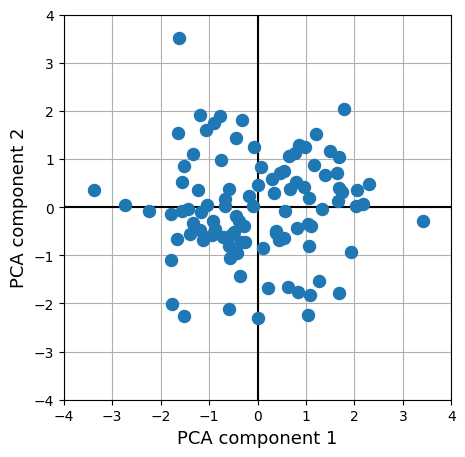
The weights of the fitted PCA model can be accessed by, confusingly, pca.components_ (shape: \(K_{lower} \times K_{higher}\). Using these weights, can you recompute the lower-dimensional features from the higher-dimensional features yourself? Try to plot it like the figure above and check whether it matches.
''' Implement the (optional) ToDo here. '''
# YOUR CODE HERE
raise NotImplementedError()
Note that dimensionality reduction is often used for visualization, but it can also be used as a preprocessing step in pattern analyses. We’ll take a look this in more detail next week.
Alright, back to the topic of pattern extraction/estimation. You saw that preparing VBM data for (between-subject) pattern analyses is actually quite straightforward, but unfortunately, preparing functional MRI data for pattern analysis is a little more complicated. The reason is that we are dealing with time series in which different trials (\(N\)) are “embedded”. The next section discusses different methods to “extract” (estimate) these trial-wise patterns.
Estimating patterns#
As we mentioned before, we should prepare our data as an \(N\) (samples) \(\times\) \(K\) (features) array. With fMRI data, our data is formatted as a \(X \times Y \times Z \times T\) array; we can flatten the \(X\), \(Y\), and \(Z\) dimensions, but we still have to find a way to “extract” patterns for our \(N\) trials from the time series (i.e., the \(T\) dimension).
Important side note: single trials vs. (runwise) average trials#
In this section, we often assume that our “samples” refer to different trials, i.e., single instances of a stimulus or response (or another experimentally-related factor). This is, however, not the only option. Sometimes, researchers choose to treat multiple repetitions of a trial as a single sample or multiple trials within a condition as a single sample. For example, suppose you design a simple passive-viewing experiment with images belonging two one of three conditions: faces, houses, and chairs. Each condition has ten exemplars (face1, face2, …, face10, house1, house2, …, house10, chair1, chair2, … , chair10) and each exemplar/item is repeated six times. So, in total there are 3 (condition) \(\times\) 10 (examplars) \(\times\) 6 (repetitions) = 180 trials. Because you don’t want to bore the participant to death, you split the 180 trials into two runs (90 each).
Now, there are different ways to define your samples. One is to treat every single trial as a sample (so you’ll have a 180 samples). Another way is to treat each exemplar as a sample. If you do so, you’ll have to “pool” the pattern estimates across all 6 repetitions (so you’ll have \(10 \times 3 = 30\) samples). And yet another way is to treat each condition as a sample, so you’ll have to pool the pattern estimates across all 6 repetitions and 10 exemplars per condition (so you’ll end up with only 3 samples). Lastly, with respect to the latter two approaches, you may choose to only average repetitions and/or exemplars within runs. So, for two runs, you end up with either \(10 \times 3 \times 2 = 60\) samples (when averaging across repetitions only) or \(3 \times 2 = 6\) samples (when averaging across examplars and repetitions).
Whether you should perform your pattern analysis on the trial, examplar, or condition level, and whether you should estimate these patterns across runs or within runs, depends on your research question and analysis technique. For example, if you want to decode exemplars from each other, you obviously should not average across exemplars. Also, some experiments may not have different exemplars per condition (or do not have categorical conditions at all). With respect to the importance of analysis technique: when applying machine learning analyses to fMRI data, people often prefer to split their trials across many (short) runs and — if using a categorical design — prefer to estimate a single pattern per run. This is because samples across runs are not temporally autocorrelated, which is an important assumption in machine learning based analyses. Lastly, for any pattern analysis, averaging across different trials will increase the signal-to-noise ratio (SNR) for any sample (because you average out noise), but will decrease the statistical power of the analysis (because you have fewer samples).
Long story short: whatever you treat as a sample — single trials, (runwise) exemplars or (runwise) conditions — depends on your design, research question, and analysis technique. In the rest of the tutorial, we will usually refer to samples as “trials”, as this scenario is easiest to simulate and visualize, but remember that this term may equally well refer to (runwise) exemplar-average or condition-average patterns.
To make the issue of estimating patterns from time series a little more concrete, let’s simulate some signals. We’ll assume that we have a very simple experiment with two conditions (A, B) with ten trials each (interleaved, i.e., ABABAB…AB), a trial duration of 1 second, spaced evenly within a single run of 200 seconds (with a TR of 2 seconds, so 100 timepoints). Note that you are not necessarily limited to discrete categorical designs for all pattern analyses! While for machine learning-based methods (topic of week 2) it is common to have a design with a single categorical feature of interest (or some times a single continuous one), representional similarity analyses (topic of week 3) are often applied to data with more “rich” designs (i.e., designs that include many, often continuously varying, factors of interest). Also, using twenty trials is probably way too few for any pattern analysis, but it’ll make the examples (and visualizations) in this section easier to understand.
Alright, let’s get to it.
TR = 2
N = 20 # 2 x 10 trials
T = 200 # duration in seconds
# t_pad is a little baseline at the
# start and end of the run
t_pad = 10
onsets = np.linspace(t_pad, T - t_pad, N, endpoint=False)
durations = np.ones(onsets.size)
conditions = ['A', 'B'] * (N // 2)
print("Onsets:", onsets, end='\n\n')
print("Conditions:", conditions)
Onsets: [ 10. 19. 28. 37. 46. 55. 64. 73. 82. 91. 100. 109. 118. 127.
136. 145. 154. 163. 172. 181.]
Conditions: ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B', 'A', 'B']
We’ll use the simulate_signal function used in the introductory course to simulate the data. This function is like a GLM in reverse: it assumes that a signal (\(R\)) is generated as a linear combination between (HRF-convolved) experimental features (\(\mathbf{S}\)) weighted by some parameters ( \(\beta\) ) plus some additive noise (\(\epsilon\)), and simulates the signal accordingly (you can check out the function by running simulate_signal?? in a new code cell).
Because we simulate the signal, we can use “ground-truth” activation parameters ( \(\beta\) ). In this simulation, we’ll determine that the signal responds more strongly to trials of condition A (\(\beta = 0.8\)) than trials of condition B (\(\beta = 0.2\)) in even voxels (voxel 0, 2, etc.) and vice versa for odd voxels (voxel 1, 3, etc.):
params_even = np.array([0.8, 0.2])
params_odd = 1 - params_even
Alright, We simulate some data for, let’s say, four voxels (\(K = 4\)). (Again, you’ll usually perform pattern analyses on many more voxels.)
from niedu.utils.nii import simulate_signal
K = 4
ts = []
for i in range(K):
# Google "Python modulo" to figure out
# what the line below does!
is_even = (i % 2) == 0
sig, _ = simulate_signal(
onsets,
conditions,
duration=T,
plot=False,
std_noise=0.25,
params_canon=params_even if is_even else params_odd
)
ts.append(sig[:, np.newaxis])
# ts = timeseries
ts = np.hstack(ts)
print("Shape of simulated signals: ", ts.shape)
Shape of simulated signals: (100, 4)
And let’s plot these voxels. We’ll show the trial onsets as arrows (red = condition A, orange = condition B):
import seaborn as sns
fig, axes = plt.subplots(ncols=K, sharex=True, sharey=True, figsize=(10, 12))
t = np.arange(ts.shape[0])
for i, ax in enumerate(axes.flatten()):
# Plot signal
ax.plot(ts[:, i], t, marker='o', ms=4, c='tab:blue')
# Plot trial onsets (as arrows)
for ii, to in enumerate(onsets):
color = 'tab:red' if ii % 2 == 0 else 'tab:orange'
ax.arrow(-1.5, to / TR, dy=0, dx=0.5, color=color, head_width=0.75, head_length=0.25)
ax.set_xlim(-1.5, 2)
ax.set_ylim(0, ts.shape[0])
ax.grid()
ax.set_title(f'Voxel {i+1}', fontsize=15)
ax.invert_yaxis()
if i == 0:
ax.set_ylabel("Time (volumes)", fontsize=20)
# Common axis labels
fig.text(0.425, -.03, "Activation (A.U.)", fontsize=20)
fig.tight_layout()
sns.despine()
plt.show()
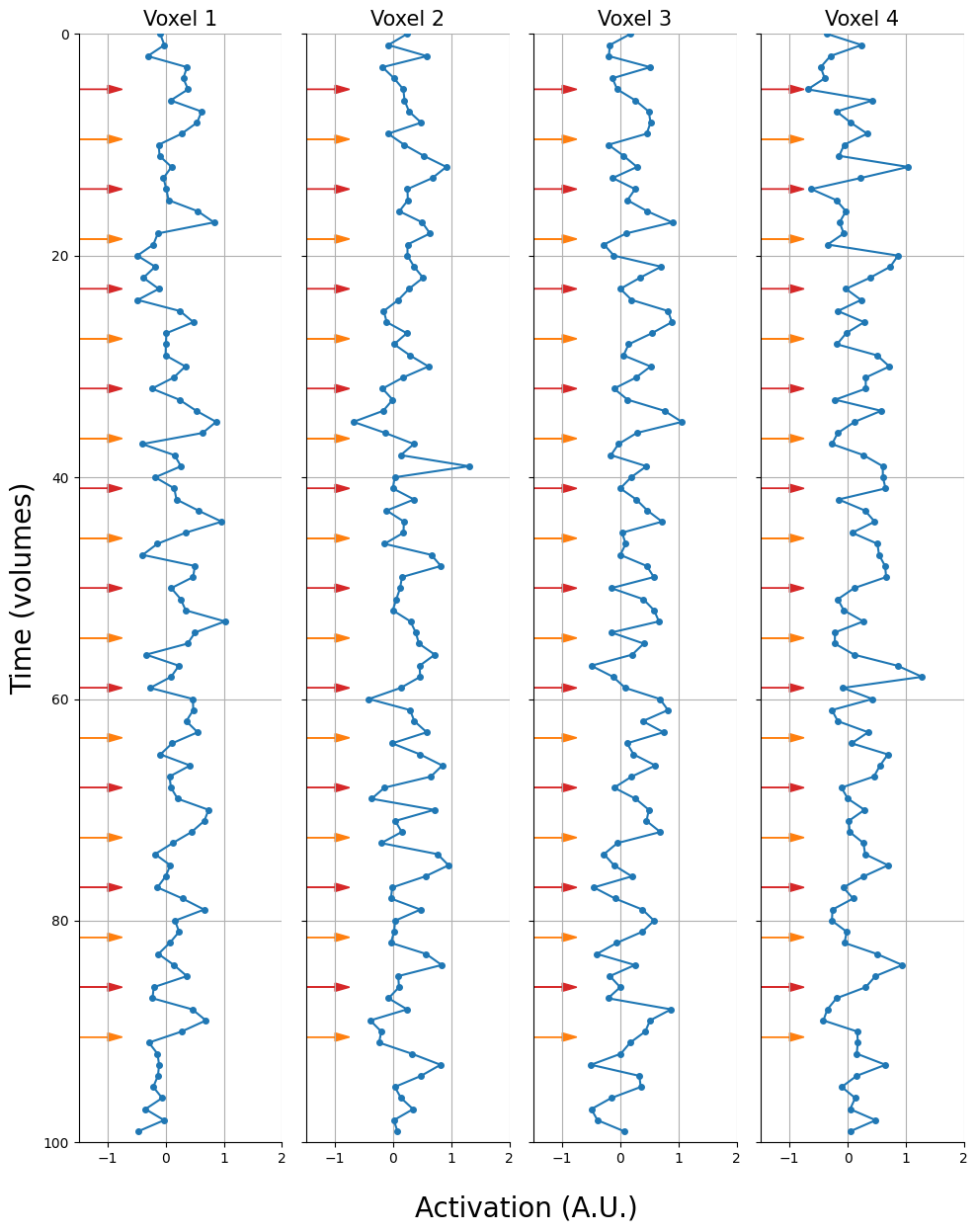
Alright, now we can start discussing methods for pattern estimation! Unfortunately, as pattern analyses are relatively new, there no concensus yet about the “best” method for pattern estimation. In fact, there exist many different methods, which we can roughly divided into two types:
Timepoint-based method (for lack of a better name) and
GLM-based methods
We’ll discuss both of them, but spend a little more time on the latter set of methods as they are more complicated (and are more popular).
Timepoint-based methods#
Timepoint-based methods “extract” patterns by simply using a single timepoint (e.g., 6 seconds after stimulus presentation) or (an average of) multiple timepoints (e.g., 4, 6, and 8 seconds after stimulus presentation).
Below, we visualize what a single-timepoint method would look like (assuming that we’d want to extract the timepoint 6 seconds after stimulus presentation, i.e., around the assumed peak of the BOLD response). The stars represent the values that we would extract (red when condition A, orange when condition B). Note, we only plot the first 60 volumes.
fig, axes = plt.subplots(ncols=4, sharex=True, sharey=True, figsize=(10, 12))
t_fmri = np.linspace(0, T, ts.shape[0], endpoint=False)
t = np.arange(ts.shape[0])
for i, ax in enumerate(axes.flatten()):
# Plot signal
ax.plot(ts[:, i], t, marker='o', ms=4, c='tab:blue')
# Plot trial onsets (as arrows)
for ii, to in enumerate(onsets):
plus6 = np.interp(to+6, t_fmri, ts[:, i])
color = 'tab:red' if ii % 2 == 0 else 'tab:orange'
ax.arrow(-1.5, to / TR, dy=0, dx=0.5, color=color, head_width=0.75, head_length=0.25)
ax.plot([plus6, plus6], [(to+6) / TR, (to+6) / TR], marker='*', ms=15, c=color)
ax.set_xlim(-1.5, 2)
ax.set_ylim(0, ts.shape[0] // 2)
ax.grid()
ax.set_title(f'Voxel {i+1}', fontsize=15)
ax.invert_yaxis()
if i == 0:
ax.set_ylabel("Time (volumes)", fontsize=20)
# Common axis labels
fig.text(0.425, -.03, "Activation (A.U.)", fontsize=20)
fig.tight_layout()
sns.despine()
plt.show()
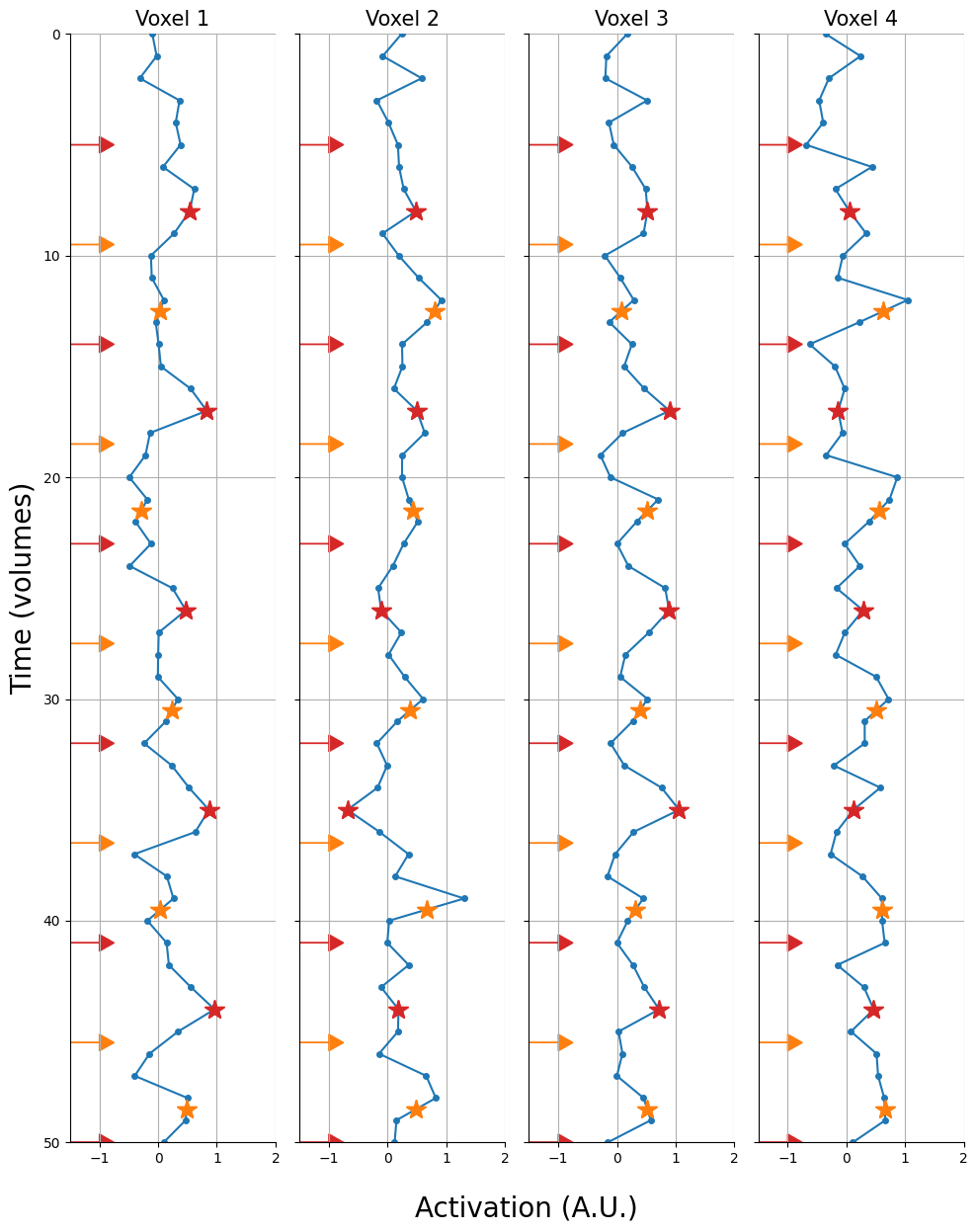
Now, extracting these timepoints 6 seconds after stimulus presentation is easy when this timepoint is a multiple of the scan’s TR (here: 2 seconds). For example, to extract the value for the first trial (onset: 10 seconds), we simply take the 8th value in our timeseries, because \((10 + 6) / 2 = 8\). But what if our trial onset + 6 seconds is not a multiple of the TR, such as with trial 2 (onset: 19 seconds)? Well, we can interpolate this value! We will use the same function for this operation as we did for slice-timing correction (from the previous course): interp1d from the scipy.interpolate module.
To refresh your memory: this function takes the timepoints associated with the values (or “frame_times” in Nilearn lingo) and the values itself to generate a new object which we’ll later use to do the actual (linear) interpolation. First, let’s define the timepoints:
t_fmri = np.linspace(0, T, ts.shape[0], endpoint=False)
''' Implement your ToDo here. '''
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_frame_times_stc
test_frame_times_stc(TR, T, ts.shape[0], t_fmri_middle_slice)
For now, let’s assume that all data was actually acquired at the start of the volume (\(t=0\), \(t=2\), etc.). We can “initialize” our interpolator by giving it both the timepoints (t_fmri) and the data (ts). Note that ts is not a single time series, but a 2D array with time series for four voxels (across different columns). By specifying axis=0, we tell interp1d that the first axis represents the axis that we want to interpolate later:
from scipy.interpolate import interp1d
interpolator = interp1d(t_fmri, ts, axis=0)
Now, we can give the interpolator object any set of timepoints and it will return the linearly interpolated values associated with these timepoints for all four voxels. Let’s do this for our trial onsets plus six seconds:
onsets_plus_6 = onsets + 6
R_plus6 = interpolator(onsets_plus_6)
print("Shape extracted pattern:", R_plus6.shape)
fig, ax = plt.subplots(figsize=(2, 10))
mapp = ax.imshow(R_plus6)
cbar = fig.colorbar(mapp)
cbar.set_label('Feature value', fontsize=13, rotation=270, labelpad=15)
ax.set_yticks(np.arange(N))
ax.set_xticks(np.arange(K))
ax.set_title(r"$\mathbf{R}$", fontsize=20)
ax.set_xlabel('Voxels', fontsize=15)
ax.set_ylabel('Trials', fontsize=15)
plt.show()
Shape extracted pattern: (20, 4)
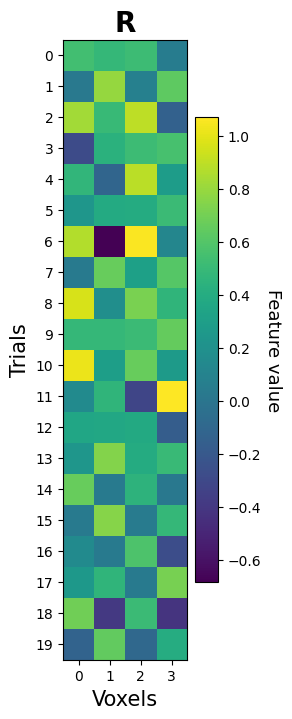
Yay, we have extracted our first pattern! Does it look like what you expected given the known mean amplitude of the trials from the two conditions (\(\beta_{\mathrm{A,even}} = 0.8, \beta_{\mathrm{B,even}} = 0.2\) and vice versa for odd voxels)?
Note: this is a relatively difficult ToDo! Consider skipping it if it takes too long.
''' Implement your ToDo here. '''
t_post_stimulus = np.linspace(5, 7, 21, endpoint=True)
print(t_post_stimulus)
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_average_extraction
test_average_extraction(onsets, ts, t_post_stimulus, interpolator, R_av)
These timepoint-based methods are relatively simple to implement and computationally efficient. Another variation that you might see in the literature is that extracted (averages of) timepoints are baseline-subtracted (\(\mathbf{R}_{i} - \mathrm{baseline}_{i}\)) or baseline-normalized (\(\frac{\mathbf{R}_{i}}{\mathrm{baseline}_{i}}\)), where the baseline is usually chosen to be at the stimulus onset or a small window before the stimulus onset. This technique is, as far as we know, not very popular, so we won’t discuss it any further in this lab.
GLM-based methods#
One big disadvantage of timepoint-based methods is that it cannot disentangle activity due to different sources (such as trials that are close in time), which is a major problem for fast (event-related) designs. For example, if you present a trial at \(t=10\) and another at \(t=12\) and subsequently extract the pattern six seconds post-stimulus (at \(t=18\) for the second trial), then the activity estimate for the second trial is definitely going to contain activity due to the first trial because of the sluggishness of the HRF.
As such, nowadays GLM-based pattern estimation techniques, which can disentangle the contribution of different sources, are more popular than timepoint-based methods. (Although, technically, you can use timepoint-based methods using the GLM with FIR-based designs, but that’s beyond the scope of this course.) Again, there are multiple flavors of GLM-based pattern estimation, of which we’ll discuss the two most popular ones.
Least-squares all (LSA)#
The most straightforward GLM-based pattern estimation technique is to fit a single GLM with a design matrix that contains one or more regressors for each sample that you want to estimate (in addition to any confound regressors). The estimated parameters (\(\hat{\beta}\)) corresponding to our samples from this GLM — representing the relative (de)activation of each voxel for each trial — will then represent our patterns!
This technique is often reffered to as “least-squares all” (LSA). Note that, as explained before, a sample can refer to either a single trial, a set of repetitions of a particuar exemplar, or even a single condition. For now, we’ll assume that samples refer to single trials. Often, each sample is modelled by a single (canonical) HRF-convolved regressor (but you could also use more than one regressor, e.g., using a basis set with temporal/dispersion derivatives or a FIR-based basis set), so we’ll focus on this approach.
Let’s go back to our simulated data. We have a single run containing 20 trials, so ultimately our design matrix should contain twenty columns: one for every trial. We can use the make_first_level_design_matrix function from Nilearn to create the design matrix. Importantly, we should make sure to give a separate and unique “trial_type” values for all our trials. If we don’t do this (e.g., set trial type to the trial condition: “A” or “B”), then Nilearn won’t create separate regressors for our trials.
import pandas as pd
from nilearn.glm.first_level import make_first_level_design_matrix
# We have to create a dataframe with onsets/durations/trial_types
# No need for modulation!
events_sim = pd.DataFrame(onsets, columns=['onset'])
events_sim.loc[:, 'duration'] = 1
events_sim.loc[:, 'trial_type'] = ['trial_' + str(i).zfill(2) for i in range(1, N+1)]
# lsa_dm = least squares all design matrix
lsa_dm = make_first_level_design_matrix(
frame_times=t_fmri, # we defined this earlier for interpolation!
events=events_sim,
hrf_model='glover',
drift_model=None # assume data is already high-pass filtered
)
# Check out the created design matrix
# Note that the index represents the frame times
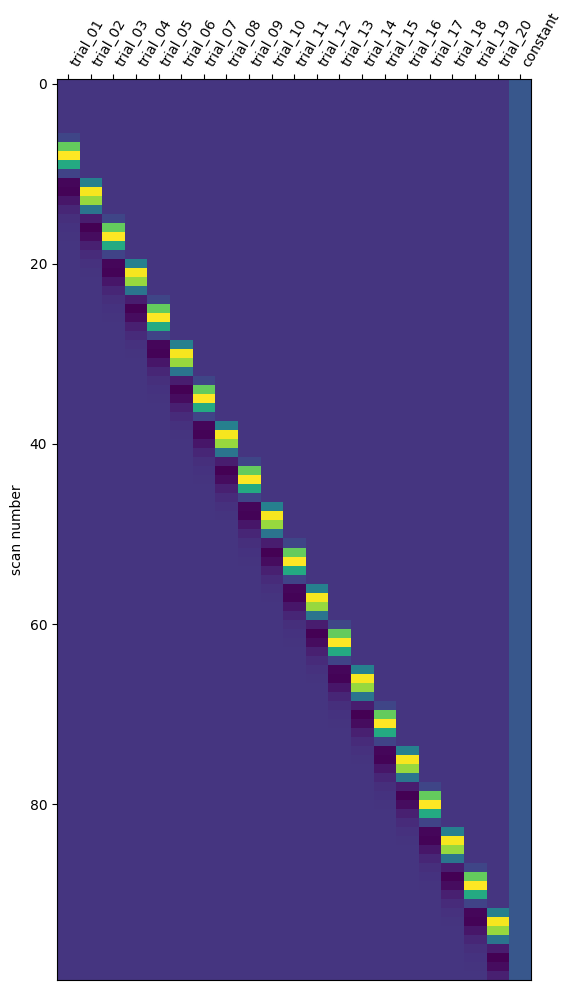
lsa_dm
| trial_01 | trial_02 | trial_03 | trial_04 | trial_05 | trial_06 | trial_07 | trial_08 | trial_09 | trial_10 | ... | trial_12 | trial_13 | trial_14 | trial_15 | trial_16 | trial_17 | trial_18 | trial_19 | trial_20 | constant | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| 4.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| 6.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| 8.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 190.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000116 | -0.014879 | 0.072992 | 1.0 |
| 192.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000031 | -0.006204 | -0.023424 | 1.0 |
| 194.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000008 | -0.002255 | -0.049163 | 1.0 |
| 196.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | -0.000734 | -0.038630 | 1.0 |
| 198.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | -0.000218 | -0.021623 | 1.0 |
100 rows × 21 columns
Note that the design matrix contains 21 regressors: 20 trialwise regressors and an intercept (the last column). Let’s also plot it using Nilearn:
from nilearn.plotting import plot_design_matrix
plot_design_matrix(lsa_dm);
And, while we’re at it, plot it as time series (rather than a heatmap):
fig, ax = plt.subplots(figsize=(12, 12))
for i in range(lsa_dm.shape[1]):
ax.plot(i + lsa_dm.iloc[:, i], np.arange(ts.shape[0]))
ax.set_title("LSA design matrix", fontsize=20)
ax.set_ylim(0, lsa_dm.shape[0]-1)
ax.set_xlabel('')
ax.set_xticks(np.arange(N+1))
ax.set_xticklabels(['trial ' + str(i+1) for i in range(N)] + ['icept'], rotation=-90)
ax.invert_yaxis()
ax.grid()
ax.set_ylabel("Time (volumes)", fontsize=15)
plt.show()
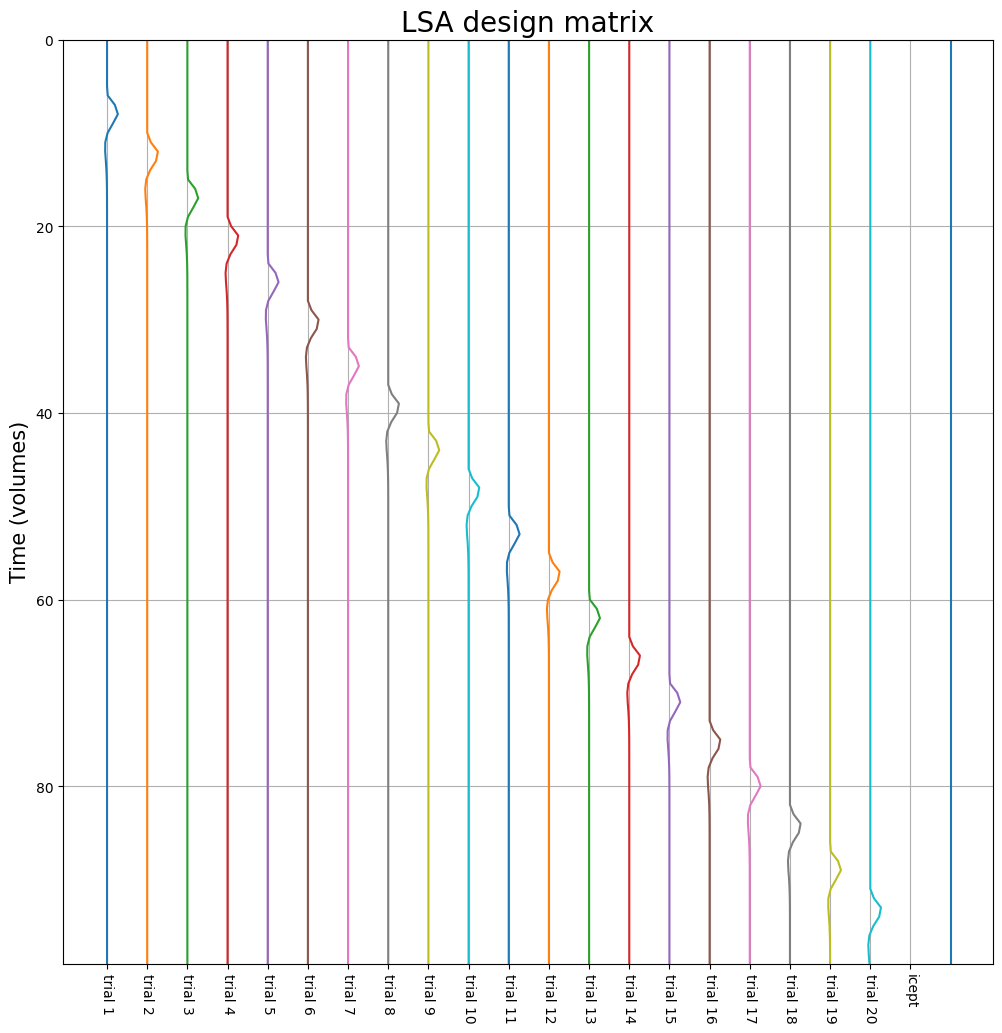
Compute the correlation between, for example, the predictors associated with trial 1 and trial 2, using the pearsonr function imported below, and store it in a variable named corr_t1t2 (1 point). Then, try to think of a way to improve the efficiency of this particular LSA design and write it down in the cell below the test cell.
''' Implement your ToDO here. '''
# For more info about the `pearsonr` function, check
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.pearsonr.html
# Want a challenge? Try to compute the correlation from scratch!
from scipy.stats import pearsonr
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the ToDo above. '''
from niedu.tests.nipa.week_1 import test_t1t2_corr
test_t1t2_corr(lsa_dm, corr_t1t2)
YOUR ANSWER HERE
Alright, let’s actually fit the model! When dealing with real fMRI data, we’d use Nilearn to fit our GLM, but for now, we’ll just use our own implementation of an (OLS) GLM. Note that we can actually fit a single GLM for all voxels at the same time by using ts (a \(T \times K\) matrix) as our dependent variable due to the magic of linear algebra. In other words, we can run \(K\) OLS models at once!
# Let's use 'X', because it's shorter
X = lsa_dm.values
# Note we can fit our GLM for all K voxels at
# the same time! As such, betas is not a vector,
# but an n_regressor x k_voxel matrix!
beta_hat_all = np.linalg.inv(X.T @ X) @ X.T @ ts
print("Shape beta_hat_all:", beta_hat_all.shape)
# Ah, the beta for the intercept is still in there
# Let's remove it
beta_icept = beta_hat_all[-1, :]
beta_hat = beta_hat_all[:-1, :]
print("Shape beta_hat (intercept removed):", beta_hat.shape)
Shape beta_hat_all: (21, 4)
Shape beta_hat (intercept removed): (20, 4)
Alright, let’s visualize the estimated parameters (\(\hat{\beta}\)). We’ll do this by plotting the scaled regressors (i.e., \(X_{j}\hat{\beta}_{j}\)) on top of the original signal. Each differently colored line represents a different regressor (so a different trial):
fig, axes = plt.subplots(ncols=4, sharex=True, sharey=True, figsize=(10, 12))
t = np.arange(ts.shape[0])
for i, ax in enumerate(axes.flatten()):
# Plot signal
ax.plot(ts[:, i], t, marker='o', ms=4, lw=0.5, c='tab:blue')
# Plot trial onsets (as arrows)
for ii, to in enumerate(onsets):
color = 'tab:red' if ii % 2 == 0 else 'tab:orange'
ax.arrow(-1.5, to / TR, dy=0, dx=0.5, color=color, head_width=0.75, head_length=0.25)
# Compute x*beta for icept only
scaled_icept = lsa_dm.iloc[:, -1].values * beta_icept[i]
for ii in range(N):
this_x = lsa_dm.iloc[:, ii].values
# Compute x*beta for this particular trial (ii)
xb = scaled_icept + this_x * beta_hat[ii, i]
ax.plot(xb, t, lw=2)
ax.set_xlim(-1.5, 2)
ax.set_ylim(0, ts.shape[0] // 2)
ax.grid()
ax.set_title(f'Voxel {i+1}', fontsize=15)
ax.invert_yaxis()
if i == 0:
ax.set_ylabel("Time (volumes)", fontsize=20)
# Common axis labels
fig.text(0.425, -.03, "Activation (A.U.)", fontsize=20)
fig.tight_layout()
sns.despine()
plt.show()
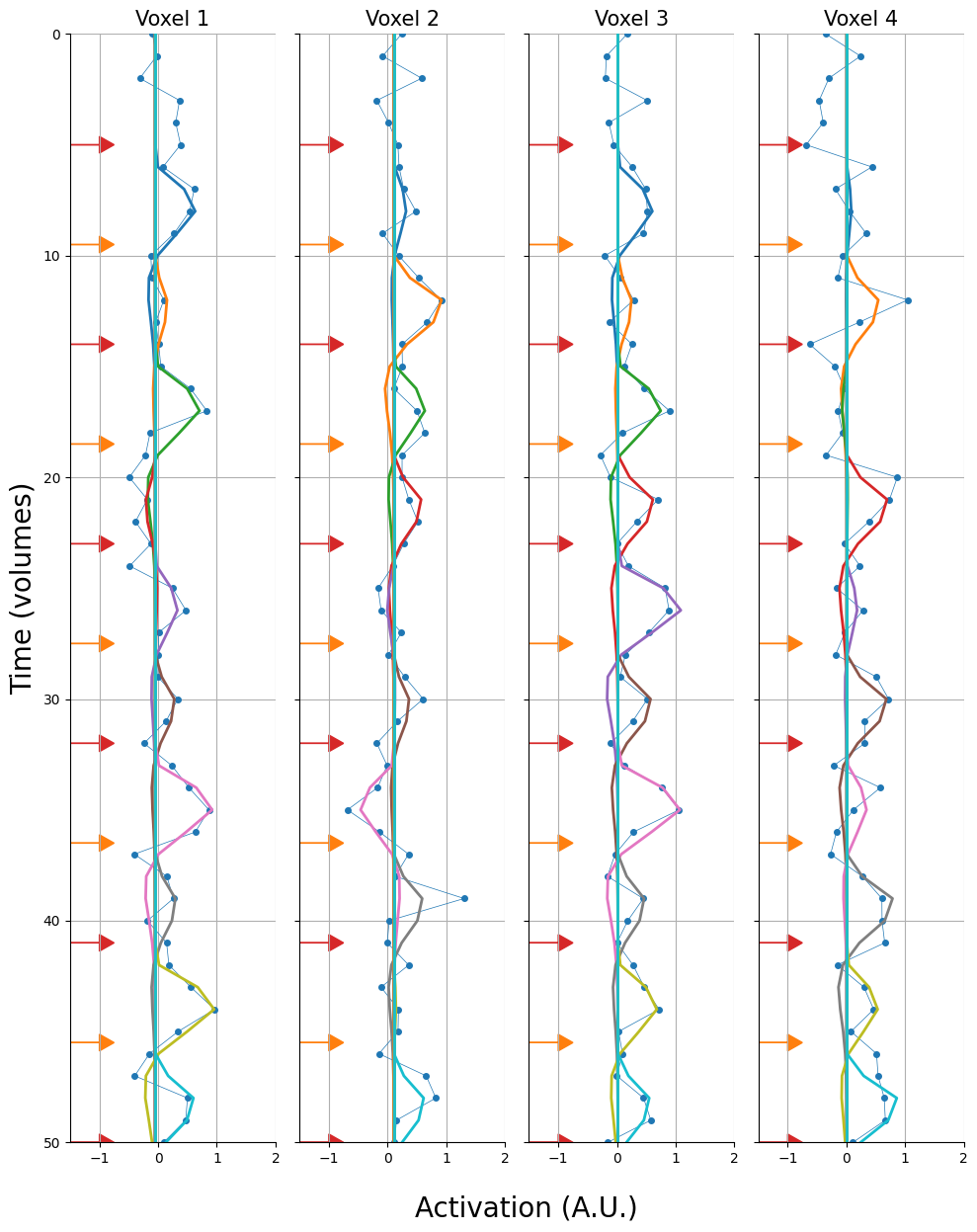
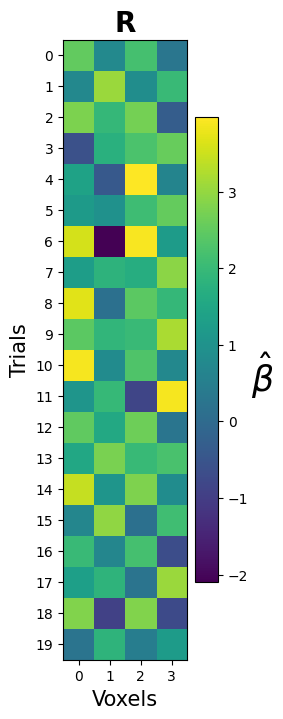
Ultimately, though, the estimated GLM parameters are just another way to estimate our pattern array (\(\mathbf{R}\)) — this time, we just estimated it using a different method (GLM-based) than before (timepoint-based). Therefore, let’s visualize this array as we did with the other methods:
fig, ax = plt.subplots(figsize=(2, 10))
mapp = ax.imshow(beta_hat)
cbar = fig.colorbar(mapp)
cbar.set_label(r'$\hat{\beta}$', fontsize=25, rotation=0, labelpad=10)
ax.set_yticks(np.arange(N))
ax.set_xticks(np.arange(K))
ax.set_title(r"$\mathbf{R}$", fontsize=20)
ax.set_xlabel('Voxels', fontsize=15)
ax.set_ylabel('Trials', fontsize=15)
plt.show()
PCA to the rescue! Run PCA on the estimated patterns (beta_hat) and store the PCA-transformed array (shape: $20 \times 2$) in a variable named beta_hat_2d. Then, try to plot the first two components as a scatterplot. Make it even nicer by plotting the trials from condition A as red points and trials from condition B als orange points.
# YOUR CODE HERE
raise NotImplementedError()
from niedu.tests.nipa.week_1 import test_pca_beta_hat
test_pca_beta_hat(beta_hat, beta_hat_2d)
Noise normalization#
One often used preprocessing step for pattern analyses (using GLM-estimation methods) is to use “noise normalization” on the estimated patterns. There are two flavours: “univariate” and “multivariate” noise normalization. In univariate noise normalization, the estimated parameters (\(\hat{\beta}\)) are divided (normalized) by the standard deviation of the estimated parameters — which you might recognize as the formula for \(t\)-values (for a contrast against baseline)!
where \(\hat{\sigma}^{2}\) is the estimate of the error variance (sum of squared errors divided by the degrees of freedom) and \(c(X^{T}X)^{-1}c^{T}\) is the “design variance”. Sometimes people disregard the design variance and the degrees of freedom (DF) and instead only use the standard deviation of the noise:
YOUR ANSWER HERE
Either way, this univariate noise normalization is a way to “down-weigh” the uncertain (noisy) parameter estimates. Although this type of univariate noise normalization seems to lead to better results in both decoding and RSA analyses (e.g., Misaki et al., 2010), the jury is still out on this issue.
Multivariate noise normalization will be discussed in week 3 (RSA), so let’s focus for now on the implementation of univariate noise normalization using the approximate method (which disregards design variance). To compute the standard deviation of the noise (\(\sqrt{\sum (y_{i} - X_{i}\hat{\beta})^{2}}\)), we first need to compute the noise, i.e., the unexplained variance (\(y - X\hat{\beta}\)) also known as the residuals:
residuals = ts - X @ beta_hat_all
print("Shape residuals:", residuals.shape)
Shape residuals: (100, 4)
So, for each voxel (\(K=4\)), we have a timeseries (\(T=100\)) with unexplained variance (“noise”). Now, to get the standard deviation across all voxels, we can do the following:
std_noise = np.std(residuals, axis=0)
print("Shape noise std:", std_noise.shape)
Shape noise std: (4,)
To do the actual normalization step, we simply divide the columns of the pattern matrix (beta_hat, which we estimated before) by the estimated noise standard deviation:
# unn = univariate noise normalization
# Note that we don't have to do this for each trial (row) separately
# due to Numpy broadcasting!
R_unn = beta_hat / std_noise
print("Shape R_unn:", R_unn.shape)
Shape R_unn: (20, 4)
And let’s visualize it:
fig, ax = plt.subplots(figsize=(2, 10))
mapp = ax.imshow(R_unn)
cbar = fig.colorbar(mapp)
cbar.set_label(r'$t$', fontsize=25, rotation=0, labelpad=10)
ax.set_yticks(np.arange(N))
ax.set_xticks(np.arange(K))
ax.set_title(r"$\mathbf{R}_{unn}$", fontsize=20)
ax.set_xlabel('Voxels', fontsize=15)
ax.set_ylabel('Trials', fontsize=15)
plt.show()
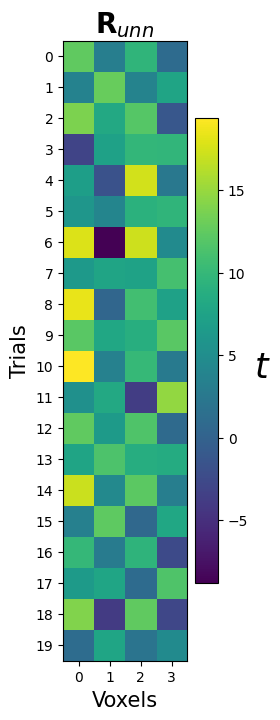
YOUR ANSWER HERE
LSA on real data#
Alright, enough with all that fake data — let’s work with some real data! We’ll use the face perception task data from the NI-edu dataset, which we briefly mentioned in the fMRI-introduction course.
In the face perception task, participants were presented with images of faces (from the publicly available Face Research Lab London Set). In total, frontal face images from 40 different people (“identities”) were used, which were either without expression (“neutral”) or were smiling. Each face image (from in total 80 faces, i.e., 40 identities \(\times\) 2, neutral/smiling) was shown, per participant, 6 times across the 12 runs (3 times per session).
Identities were counterbalanced in terms of biological sex (male vs. female) and ethnicity (Caucasian vs. East-Asian vs. Black). The Face Research Lab London Set also contains the age of the people in the stimulus dataset and (average) attractiveness ratings for all faces from an independent set of raters. In addition, we also had our own participants rate the faces on perceived attractiveness, dominance, and trustworthiness after each session (rating each face, on each dimension, four times in total for robustness). The stimuli were chosen such that we have many different attributes that we could use to model brain responses (e.g., identity, expression, ethnicity, age, average attractiveness, and subjective/personal perceived attractiveness/dominance/trustworthiness).
In this paradigm, stimuli were presented for 1.25 seconds and had a fixed interstimulus interval (ISI) of 3.75 seconds. While sub-optimal for univariate “detection-based” analyses, we used a fixed ISI — rather than jittered — to make sure it can also be used for “single-trial” multivariate analyses. Each run contained 40 stimulus presentations. To keep the participants attentive, a random selection of 5 stimuli (out of 40) were followed by a rating on either perceived attractiveness, dominance, or trustworthiness using a button-box with eight buttons (four per hand) lasting 2.5 seconds. After the rating, a regular ISI of 3.75 seconds followed. See the figure below for a visualization of the paradigm.
First, let’s set up all the data that we need for our LSA model. Let’s see where our data is located:
import os
data_dir = os.path.join(os.path.expanduser('~'), 'NI-edu-data')
print("Downloading Fmriprep data (+- 175MB) ...\n")
!aws s3 sync --no-sign-request s3://openneuro.org/ds003965 {data_dir} --exclude "*" --include "sub-03/ses-1/func/*task-face*run-1*events.tsv"
!aws s3 sync --no-sign-request s3://openneuro.org/ds003965 {data_dir} --exclude "*" --include "derivatives/fmriprep/sub-03/ses-1/func/*task-face*run-1*space-T1w*bold.nii.gz"
!aws s3 sync --no-sign-request s3://openneuro.org/ds003965 {data_dir} --exclude "*" --include "derivatives/fmriprep/sub-03/ses-1/func/*task-face*run-1*space-T1w*mask.nii.gz"
!aws s3 sync --no-sign-request s3://openneuro.org/ds003965 {data_dir} --exclude "*" --include "derivatives/fmriprep/sub-03/ses-1/func/*task-face*run-1*confounds_timeseries.tsv"
print("\nDone!")
Downloading Fmriprep data (+- 175MB) ...
Completed 7.2 KiB/7.2 KiB (53.2 KiB/s) with 1 file(s) remaining
download: s3://openneuro.org/ds003965/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_events.tsv to ../../../../../../NI-edu-data/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_events.tsv
Completed 256.0 KiB/~172.7 MiB (324.3 KiB/s) with ~1 file(s) remaining (calculating...)
Completed 512.0 KiB/~172.7 MiB (642.8 KiB/s) with ~1 file(s) remaining (calculating...)
Completed 768.0 KiB/~172.7 MiB (963.2 KiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.0 MiB/~172.7 MiB (1.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.2 MiB/~172.7 MiB (1.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.5 MiB/~172.7 MiB (1.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.8 MiB/~172.7 MiB (2.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 2.0 MiB/~172.7 MiB (2.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 2.2 MiB/~172.7 MiB (2.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 2.5 MiB/~172.7 MiB (3.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 2.8 MiB/~172.7 MiB (3.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 3.0 MiB/~172.7 MiB (3.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 3.2 MiB/~172.7 MiB (4.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 3.5 MiB/~172.7 MiB (4.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 3.8 MiB/~172.7 MiB (4.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 4.0 MiB/~172.7 MiB (4.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 4.2 MiB/~172.7 MiB (5.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 4.5 MiB/~172.7 MiB (5.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 4.8 MiB/~172.7 MiB (5.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 5.0 MiB/~172.7 MiB (6.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 5.2 MiB/~172.7 MiB (6.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 5.5 MiB/~172.7 MiB (6.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 5.8 MiB/~172.7 MiB (6.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 6.0 MiB/~172.7 MiB (7.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 6.2 MiB/~172.7 MiB (7.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 6.5 MiB/~172.7 MiB (7.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 6.8 MiB/~172.7 MiB (8.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 7.0 MiB/~172.7 MiB (8.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 7.2 MiB/~172.7 MiB (8.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 7.5 MiB/~172.7 MiB (8.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 7.8 MiB/~172.7 MiB (9.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 8.0 MiB/~172.7 MiB (9.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 8.2 MiB/~172.7 MiB (9.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 8.5 MiB/~172.7 MiB (9.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 8.8 MiB/~172.7 MiB (10.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 9.0 MiB/~172.7 MiB (10.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 9.2 MiB/~172.7 MiB (10.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 9.5 MiB/~172.7 MiB (10.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 9.8 MiB/~172.7 MiB (10.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 10.0 MiB/~172.7 MiB (11.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 10.2 MiB/~172.7 MiB (11.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 10.5 MiB/~172.7 MiB (11.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 10.8 MiB/~172.7 MiB (11.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 11.0 MiB/~172.7 MiB (12.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 11.2 MiB/~172.7 MiB (12.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 11.5 MiB/~172.7 MiB (12.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 11.8 MiB/~172.7 MiB (12.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 12.0 MiB/~172.7 MiB (13.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 12.2 MiB/~172.7 MiB (13.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 12.5 MiB/~172.7 MiB (13.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 12.8 MiB/~172.7 MiB (13.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 13.0 MiB/~172.7 MiB (14.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 13.2 MiB/~172.7 MiB (14.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 13.5 MiB/~172.7 MiB (14.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 13.8 MiB/~172.7 MiB (14.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 14.0 MiB/~172.7 MiB (14.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 14.2 MiB/~172.7 MiB (14.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 14.5 MiB/~172.7 MiB (14.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 14.8 MiB/~172.7 MiB (14.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 15.0 MiB/~172.7 MiB (15.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 15.2 MiB/~172.7 MiB (15.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 15.5 MiB/~172.7 MiB (15.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 15.8 MiB/~172.7 MiB (15.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 16.0 MiB/~172.7 MiB (16.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 16.2 MiB/~172.7 MiB (16.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 16.5 MiB/~172.7 MiB (16.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 16.8 MiB/~172.7 MiB (16.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 17.0 MiB/~172.7 MiB (16.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 17.2 MiB/~172.7 MiB (17.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 17.5 MiB/~172.7 MiB (17.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 17.8 MiB/~172.7 MiB (17.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 18.0 MiB/~172.7 MiB (17.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 18.2 MiB/~172.7 MiB (18.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 18.5 MiB/~172.7 MiB (18.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 18.8 MiB/~172.7 MiB (18.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 19.0 MiB/~172.7 MiB (18.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 19.2 MiB/~172.7 MiB (19.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 19.5 MiB/~172.7 MiB (19.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 19.8 MiB/~172.7 MiB (19.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 20.0 MiB/~172.7 MiB (19.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 20.2 MiB/~172.7 MiB (19.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 20.5 MiB/~172.7 MiB (19.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 20.8 MiB/~172.7 MiB (19.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 21.0 MiB/~172.7 MiB (19.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 21.2 MiB/~172.7 MiB (20.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 21.5 MiB/~172.7 MiB (20.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 21.8 MiB/~172.7 MiB (20.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 22.0 MiB/~172.7 MiB (20.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 22.2 MiB/~172.7 MiB (21.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 22.5 MiB/~172.7 MiB (21.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 22.8 MiB/~172.7 MiB (21.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 23.0 MiB/~172.7 MiB (21.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 23.2 MiB/~172.7 MiB (21.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 23.5 MiB/~172.7 MiB (21.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 23.8 MiB/~172.7 MiB (22.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 24.0 MiB/~172.7 MiB (22.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 24.2 MiB/~172.7 MiB (22.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 24.5 MiB/~172.7 MiB (22.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 24.8 MiB/~172.7 MiB (22.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 25.0 MiB/~172.7 MiB (22.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 25.2 MiB/~172.7 MiB (22.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 25.5 MiB/~172.7 MiB (22.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 25.8 MiB/~172.7 MiB (23.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 26.0 MiB/~172.7 MiB (23.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 26.2 MiB/~172.7 MiB (23.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 26.5 MiB/~172.7 MiB (23.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 26.8 MiB/~172.7 MiB (23.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 27.0 MiB/~172.7 MiB (23.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 27.2 MiB/~172.7 MiB (23.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 27.5 MiB/~172.7 MiB (23.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 27.8 MiB/~172.7 MiB (23.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 28.0 MiB/~172.7 MiB (23.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 28.2 MiB/~172.7 MiB (24.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 28.5 MiB/~172.7 MiB (24.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 28.8 MiB/~172.7 MiB (24.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 29.0 MiB/~172.7 MiB (24.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 29.2 MiB/~172.7 MiB (24.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 29.5 MiB/~172.7 MiB (25.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 29.8 MiB/~172.7 MiB (25.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 30.0 MiB/~172.7 MiB (25.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 30.2 MiB/~172.7 MiB (25.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 30.5 MiB/~172.7 MiB (25.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 30.8 MiB/~172.7 MiB (25.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 31.0 MiB/~172.7 MiB (26.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 31.2 MiB/~172.7 MiB (26.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 31.5 MiB/~172.7 MiB (26.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 31.8 MiB/~172.7 MiB (26.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 32.0 MiB/~172.7 MiB (26.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 32.2 MiB/~172.7 MiB (27.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 32.5 MiB/~172.7 MiB (27.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 32.8 MiB/~172.7 MiB (27.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 33.0 MiB/~172.7 MiB (27.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 33.2 MiB/~172.7 MiB (27.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 33.5 MiB/~172.7 MiB (28.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 33.8 MiB/~172.7 MiB (28.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 34.0 MiB/~172.7 MiB (28.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 34.2 MiB/~172.7 MiB (28.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 34.5 MiB/~172.7 MiB (28.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 34.8 MiB/~172.7 MiB (28.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 35.0 MiB/~172.7 MiB (29.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 35.2 MiB/~172.7 MiB (29.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 35.5 MiB/~172.7 MiB (29.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 35.8 MiB/~172.7 MiB (29.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 36.0 MiB/~172.7 MiB (29.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 36.2 MiB/~172.7 MiB (30.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 36.5 MiB/~172.7 MiB (30.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 36.8 MiB/~172.7 MiB (30.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 37.0 MiB/~172.7 MiB (30.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 37.2 MiB/~172.7 MiB (30.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 37.5 MiB/~172.7 MiB (30.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 37.8 MiB/~172.7 MiB (31.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 38.0 MiB/~172.7 MiB (31.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 38.2 MiB/~172.7 MiB (31.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 38.5 MiB/~172.7 MiB (31.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 38.8 MiB/~172.7 MiB (31.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 39.0 MiB/~172.7 MiB (32.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 39.2 MiB/~172.7 MiB (32.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 39.5 MiB/~172.7 MiB (32.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 39.8 MiB/~172.7 MiB (32.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 40.0 MiB/~172.7 MiB (32.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 40.2 MiB/~172.7 MiB (32.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 40.5 MiB/~172.7 MiB (33.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 40.8 MiB/~172.7 MiB (33.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 41.0 MiB/~172.7 MiB (33.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 41.2 MiB/~172.7 MiB (33.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 41.5 MiB/~172.7 MiB (33.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 41.8 MiB/~172.7 MiB (33.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 42.0 MiB/~172.7 MiB (34.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 42.2 MiB/~172.7 MiB (34.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 42.5 MiB/~172.7 MiB (34.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 42.8 MiB/~172.7 MiB (34.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 43.0 MiB/~172.7 MiB (34.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 43.2 MiB/~172.7 MiB (34.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 43.5 MiB/~172.7 MiB (35.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 43.8 MiB/~172.7 MiB (35.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 44.0 MiB/~172.7 MiB (35.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 44.2 MiB/~172.7 MiB (35.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 44.5 MiB/~172.7 MiB (35.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 44.8 MiB/~172.7 MiB (36.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 45.0 MiB/~172.7 MiB (36.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 45.2 MiB/~172.7 MiB (36.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 45.5 MiB/~172.7 MiB (36.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 45.8 MiB/~172.7 MiB (36.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 46.0 MiB/~172.7 MiB (36.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 46.2 MiB/~172.7 MiB (37.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 46.5 MiB/~172.7 MiB (37.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 46.8 MiB/~172.7 MiB (37.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 47.0 MiB/~172.7 MiB (37.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 47.2 MiB/~172.7 MiB (37.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 47.5 MiB/~172.7 MiB (37.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 47.8 MiB/~172.7 MiB (38.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 48.0 MiB/~172.7 MiB (38.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 48.2 MiB/~172.7 MiB (38.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 48.5 MiB/~172.7 MiB (38.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 48.8 MiB/~172.7 MiB (38.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 49.0 MiB/~172.7 MiB (38.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 49.2 MiB/~172.7 MiB (39.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 49.5 MiB/~172.7 MiB (39.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 49.8 MiB/~172.7 MiB (39.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 50.0 MiB/~172.7 MiB (39.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 50.2 MiB/~172.7 MiB (39.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 50.5 MiB/~172.7 MiB (39.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 50.8 MiB/~172.7 MiB (40.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 51.0 MiB/~172.7 MiB (40.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 51.2 MiB/~172.7 MiB (40.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 51.5 MiB/~172.7 MiB (40.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 51.8 MiB/~172.7 MiB (40.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 52.0 MiB/~172.7 MiB (40.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 52.2 MiB/~172.7 MiB (40.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 52.5 MiB/~172.7 MiB (41.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 52.8 MiB/~172.7 MiB (41.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 53.0 MiB/~172.7 MiB (41.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 53.2 MiB/~172.7 MiB (41.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 53.5 MiB/~172.7 MiB (41.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 53.8 MiB/~172.7 MiB (41.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 54.0 MiB/~172.7 MiB (41.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 54.2 MiB/~172.7 MiB (42.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 54.5 MiB/~172.7 MiB (42.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 54.8 MiB/~172.7 MiB (42.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 55.0 MiB/~172.7 MiB (42.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 55.2 MiB/~172.7 MiB (42.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 55.5 MiB/~172.7 MiB (41.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 55.8 MiB/~172.7 MiB (41.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 56.0 MiB/~172.7 MiB (42.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 56.2 MiB/~172.7 MiB (42.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 56.5 MiB/~172.7 MiB (42.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 56.8 MiB/~172.7 MiB (42.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 57.0 MiB/~172.7 MiB (42.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 57.2 MiB/~172.7 MiB (42.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 57.5 MiB/~172.7 MiB (42.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 57.8 MiB/~172.7 MiB (42.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 58.0 MiB/~172.7 MiB (43.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 58.2 MiB/~172.7 MiB (43.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 58.5 MiB/~172.7 MiB (43.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 58.8 MiB/~172.7 MiB (43.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 59.0 MiB/~172.7 MiB (43.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 59.2 MiB/~172.7 MiB (43.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 59.5 MiB/~172.7 MiB (44.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 59.8 MiB/~172.7 MiB (44.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 60.0 MiB/~172.7 MiB (44.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 60.2 MiB/~172.7 MiB (44.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 60.5 MiB/~172.7 MiB (44.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 60.8 MiB/~172.7 MiB (44.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 61.0 MiB/~172.7 MiB (44.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 61.2 MiB/~172.7 MiB (44.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 61.5 MiB/~172.7 MiB (44.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 61.8 MiB/~172.7 MiB (44.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 62.0 MiB/~172.7 MiB (44.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 62.2 MiB/~172.7 MiB (44.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 62.5 MiB/~172.7 MiB (44.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 62.8 MiB/~172.7 MiB (44.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 63.0 MiB/~172.7 MiB (45.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 63.2 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 63.5 MiB/~172.7 MiB (44.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 63.8 MiB/~172.7 MiB (44.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 64.0 MiB/~172.7 MiB (45.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 64.2 MiB/~172.7 MiB (45.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 64.5 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 64.8 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 65.0 MiB/~172.7 MiB (45.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 65.2 MiB/~172.7 MiB (45.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 65.5 MiB/~172.7 MiB (44.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 65.8 MiB/~172.7 MiB (44.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 66.0 MiB/~172.7 MiB (44.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 66.2 MiB/~172.7 MiB (44.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 66.5 MiB/~172.7 MiB (45.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 66.8 MiB/~172.7 MiB (45.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 67.0 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 67.2 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 67.5 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 67.8 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 68.0 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 68.2 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 68.5 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 68.8 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 69.0 MiB/~172.7 MiB (45.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 69.2 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 69.5 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 69.8 MiB/~172.7 MiB (45.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 70.0 MiB/~172.7 MiB (45.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 70.2 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 70.5 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 70.8 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 71.0 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 71.2 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 71.5 MiB/~172.7 MiB (45.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 71.8 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 72.0 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 72.2 MiB/~172.7 MiB (45.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 72.5 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 72.8 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 73.0 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 73.2 MiB/~172.7 MiB (45.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 73.5 MiB/~172.7 MiB (45.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 73.8 MiB/~172.7 MiB (45.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 74.0 MiB/~172.7 MiB (45.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 74.2 MiB/~172.7 MiB (45.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 74.5 MiB/~172.7 MiB (45.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 74.8 MiB/~172.7 MiB (45.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 75.0 MiB/~172.7 MiB (45.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 75.2 MiB/~172.7 MiB (46.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 75.5 MiB/~172.7 MiB (46.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 75.8 MiB/~172.7 MiB (46.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 76.0 MiB/~172.7 MiB (46.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 76.2 MiB/~172.7 MiB (46.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 76.5 MiB/~172.7 MiB (46.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 76.8 MiB/~172.7 MiB (46.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 77.0 MiB/~172.7 MiB (46.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 77.2 MiB/~172.7 MiB (46.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 77.5 MiB/~172.7 MiB (46.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 77.8 MiB/~172.7 MiB (46.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 78.0 MiB/~172.7 MiB (46.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 78.2 MiB/~172.7 MiB (46.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 78.5 MiB/~172.7 MiB (46.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 78.8 MiB/~172.7 MiB (46.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 79.0 MiB/~172.7 MiB (46.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 79.2 MiB/~172.7 MiB (46.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 79.5 MiB/~172.7 MiB (46.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 79.8 MiB/~172.7 MiB (46.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 80.0 MiB/~172.7 MiB (46.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 80.2 MiB/~172.7 MiB (47.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 80.5 MiB/~172.7 MiB (47.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 80.8 MiB/~172.7 MiB (47.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 81.0 MiB/~172.7 MiB (47.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 81.2 MiB/~172.7 MiB (47.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 81.5 MiB/~172.7 MiB (47.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 81.8 MiB/~172.7 MiB (47.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 82.0 MiB/~172.7 MiB (47.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 82.2 MiB/~172.7 MiB (48.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 82.5 MiB/~172.7 MiB (48.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 82.8 MiB/~172.7 MiB (48.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 83.0 MiB/~172.7 MiB (48.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 83.2 MiB/~172.7 MiB (48.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 83.5 MiB/~172.7 MiB (48.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 83.8 MiB/~172.7 MiB (48.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 84.0 MiB/~172.7 MiB (48.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 84.2 MiB/~172.7 MiB (49.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 84.5 MiB/~172.7 MiB (49.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 84.8 MiB/~172.7 MiB (49.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 85.0 MiB/~172.7 MiB (49.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 85.2 MiB/~172.7 MiB (49.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 85.5 MiB/~172.7 MiB (49.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 85.8 MiB/~172.7 MiB (49.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 86.0 MiB/~172.7 MiB (49.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 86.2 MiB/~172.7 MiB (49.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 86.5 MiB/~172.7 MiB (50.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 86.8 MiB/~172.7 MiB (50.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 87.0 MiB/~172.7 MiB (50.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 87.2 MiB/~172.7 MiB (50.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 87.5 MiB/~172.7 MiB (50.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 87.8 MiB/~172.7 MiB (50.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 88.0 MiB/~172.7 MiB (50.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 88.2 MiB/~172.7 MiB (50.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 88.5 MiB/~172.7 MiB (50.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 88.8 MiB/~172.7 MiB (51.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 89.0 MiB/~172.7 MiB (51.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 89.2 MiB/~172.7 MiB (51.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 89.5 MiB/~172.7 MiB (51.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 89.8 MiB/~172.7 MiB (51.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 90.0 MiB/~172.7 MiB (51.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 90.2 MiB/~172.7 MiB (51.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 90.5 MiB/~172.7 MiB (51.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 90.8 MiB/~172.7 MiB (51.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 91.0 MiB/~172.7 MiB (52.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 91.2 MiB/~172.7 MiB (52.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 91.5 MiB/~172.7 MiB (52.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 91.8 MiB/~172.7 MiB (52.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 92.0 MiB/~172.7 MiB (52.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 92.2 MiB/~172.7 MiB (52.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 92.5 MiB/~172.7 MiB (52.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 92.8 MiB/~172.7 MiB (52.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 93.0 MiB/~172.7 MiB (52.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 93.2 MiB/~172.7 MiB (53.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 93.5 MiB/~172.7 MiB (53.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 93.8 MiB/~172.7 MiB (53.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 94.0 MiB/~172.7 MiB (53.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 94.2 MiB/~172.7 MiB (53.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 94.5 MiB/~172.7 MiB (53.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 94.8 MiB/~172.7 MiB (53.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 95.0 MiB/~172.7 MiB (53.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 95.2 MiB/~172.7 MiB (53.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 95.5 MiB/~172.7 MiB (54.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 95.8 MiB/~172.7 MiB (54.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 96.0 MiB/~172.7 MiB (54.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 96.2 MiB/~172.7 MiB (54.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 96.5 MiB/~172.7 MiB (54.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 96.8 MiB/~172.7 MiB (54.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 97.0 MiB/~172.7 MiB (54.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 97.2 MiB/~172.7 MiB (54.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 97.5 MiB/~172.7 MiB (54.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 97.8 MiB/~172.7 MiB (55.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 98.0 MiB/~172.7 MiB (55.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 98.2 MiB/~172.7 MiB (55.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 98.5 MiB/~172.7 MiB (55.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 98.8 MiB/~172.7 MiB (55.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 99.0 MiB/~172.7 MiB (55.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 99.2 MiB/~172.7 MiB (55.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 99.5 MiB/~172.7 MiB (55.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 99.8 MiB/~172.7 MiB (55.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 100.0 MiB/~172.7 MiB (56.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 100.2 MiB/~172.7 MiB (56.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 100.5 MiB/~172.7 MiB (56.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 100.8 MiB/~172.7 MiB (56.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 101.0 MiB/~172.7 MiB (56.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 101.2 MiB/~172.7 MiB (56.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 101.5 MiB/~172.7 MiB (56.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 101.8 MiB/~172.7 MiB (56.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 102.0 MiB/~172.7 MiB (56.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 102.2 MiB/~172.7 MiB (56.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 102.5 MiB/~172.7 MiB (56.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 102.8 MiB/~172.7 MiB (56.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 103.0 MiB/~172.7 MiB (57.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 103.2 MiB/~172.7 MiB (57.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 103.5 MiB/~172.7 MiB (57.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 103.8 MiB/~172.7 MiB (57.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 104.0 MiB/~172.7 MiB (57.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 104.2 MiB/~172.7 MiB (57.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 104.5 MiB/~172.7 MiB (57.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 104.8 MiB/~172.7 MiB (57.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 105.0 MiB/~172.7 MiB (57.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 105.2 MiB/~172.7 MiB (57.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 105.5 MiB/~172.7 MiB (58.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 105.8 MiB/~172.7 MiB (58.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 106.0 MiB/~172.7 MiB (57.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 106.2 MiB/~172.7 MiB (58.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 106.5 MiB/~172.7 MiB (58.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 106.8 MiB/~172.7 MiB (58.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 107.0 MiB/~172.7 MiB (58.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 107.2 MiB/~172.7 MiB (58.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 107.5 MiB/~172.7 MiB (58.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 107.8 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 108.0 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 108.2 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 108.5 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 108.8 MiB/~172.7 MiB (58.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 109.0 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 109.2 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 109.5 MiB/~172.7 MiB (58.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 109.8 MiB/~172.7 MiB (58.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 110.0 MiB/~172.7 MiB (58.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 110.2 MiB/~172.7 MiB (58.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 110.5 MiB/~172.7 MiB (58.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 110.8 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 111.0 MiB/~172.7 MiB (58.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 111.2 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 111.5 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 111.8 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 112.0 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 112.2 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 112.5 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 112.8 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 113.0 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 113.2 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 113.5 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 113.8 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 114.0 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 114.2 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 114.5 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 114.8 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 115.0 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 115.2 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 115.5 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 115.8 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 116.0 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 116.2 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 116.5 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 116.8 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 117.0 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 117.2 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 117.5 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 117.8 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 118.0 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 118.2 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 118.5 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 118.8 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 119.0 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 119.2 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 119.5 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 119.8 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 120.0 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 120.2 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 120.5 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 120.8 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 121.0 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 121.2 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 121.5 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 121.8 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 122.0 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 122.2 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 122.5 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 122.8 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 123.0 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 123.2 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 123.5 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 123.8 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 124.0 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 124.2 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 124.5 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 124.8 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 125.0 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 125.2 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 125.5 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 125.8 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 126.0 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 126.2 MiB/~172.7 MiB (59.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 126.5 MiB/~172.7 MiB (59.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 126.8 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 127.0 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 127.2 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 127.5 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 127.8 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 128.0 MiB/~172.7 MiB (59.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 128.2 MiB/~172.7 MiB (59.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 128.5 MiB/~172.7 MiB (59.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 128.8 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 129.0 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 129.2 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 129.5 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 129.8 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 130.0 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 130.2 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 130.5 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 130.8 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 131.0 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 131.2 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 131.5 MiB/~172.7 MiB (58.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 131.8 MiB/~172.7 MiB (58.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 132.0 MiB/~172.7 MiB (58.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 132.2 MiB/~172.7 MiB (58.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 132.5 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 132.8 MiB/~172.7 MiB (58.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 133.0 MiB/~172.7 MiB (59.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 133.2 MiB/~172.7 MiB (59.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 133.5 MiB/~172.7 MiB (59.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 133.8 MiB/~172.7 MiB (59.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 134.0 MiB/~172.7 MiB (59.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 134.2 MiB/~172.7 MiB (59.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 134.5 MiB/~172.7 MiB (59.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 134.8 MiB/~172.7 MiB (59.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 135.0 MiB/~172.7 MiB (59.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 135.2 MiB/~172.7 MiB (59.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 135.5 MiB/~172.7 MiB (59.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 135.8 MiB/~172.7 MiB (60.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 136.0 MiB/~172.7 MiB (60.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 136.2 MiB/~172.7 MiB (60.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 136.5 MiB/~172.7 MiB (60.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 136.8 MiB/~172.7 MiB (60.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 137.0 MiB/~172.7 MiB (60.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 137.2 MiB/~172.7 MiB (60.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 137.5 MiB/~172.7 MiB (60.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 137.8 MiB/~172.7 MiB (60.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 138.0 MiB/~172.7 MiB (60.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 138.2 MiB/~172.7 MiB (61.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 138.5 MiB/~172.7 MiB (61.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 138.8 MiB/~172.7 MiB (61.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 139.0 MiB/~172.7 MiB (61.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 139.2 MiB/~172.7 MiB (61.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 139.5 MiB/~172.7 MiB (61.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 139.8 MiB/~172.7 MiB (61.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 140.0 MiB/~172.7 MiB (61.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 140.2 MiB/~172.7 MiB (61.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 140.5 MiB/~172.7 MiB (61.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 140.8 MiB/~172.7 MiB (61.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 141.0 MiB/~172.7 MiB (61.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 141.2 MiB/~172.7 MiB (62.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 141.5 MiB/~172.7 MiB (62.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 141.8 MiB/~172.7 MiB (62.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 142.0 MiB/~172.7 MiB (62.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 142.2 MiB/~172.7 MiB (62.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 142.5 MiB/~172.7 MiB (62.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 142.8 MiB/~172.7 MiB (62.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 143.0 MiB/~172.7 MiB (62.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 143.2 MiB/~172.7 MiB (62.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 143.5 MiB/~172.7 MiB (62.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 143.8 MiB/~172.7 MiB (62.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 144.0 MiB/~172.7 MiB (63.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 144.2 MiB/~172.7 MiB (63.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 144.5 MiB/~172.7 MiB (63.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 144.8 MiB/~172.7 MiB (63.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 145.0 MiB/~172.7 MiB (63.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 145.2 MiB/~172.7 MiB (63.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 145.5 MiB/~172.7 MiB (63.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 145.8 MiB/~172.7 MiB (63.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 146.0 MiB/~172.7 MiB (63.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 146.2 MiB/~172.7 MiB (63.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 146.5 MiB/~172.7 MiB (63.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 146.8 MiB/~172.7 MiB (63.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 147.0 MiB/~172.7 MiB (64.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 147.2 MiB/~172.7 MiB (64.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 147.5 MiB/~172.7 MiB (64.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 147.8 MiB/~172.7 MiB (64.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 148.0 MiB/~172.7 MiB (64.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 148.2 MiB/~172.7 MiB (64.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 148.5 MiB/~172.7 MiB (64.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 148.8 MiB/~172.7 MiB (64.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 149.0 MiB/~172.7 MiB (64.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 149.2 MiB/~172.7 MiB (64.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 149.5 MiB/~172.7 MiB (64.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 149.8 MiB/~172.7 MiB (64.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 150.0 MiB/~172.7 MiB (65.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 150.2 MiB/~172.7 MiB (65.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 150.5 MiB/~172.7 MiB (65.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 150.8 MiB/~172.7 MiB (65.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 151.0 MiB/~172.7 MiB (65.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 151.2 MiB/~172.7 MiB (65.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 151.5 MiB/~172.7 MiB (65.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 151.8 MiB/~172.7 MiB (65.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 152.0 MiB/~172.7 MiB (65.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 152.2 MiB/~172.7 MiB (65.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 152.4 MiB/~172.7 MiB (65.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 152.7 MiB/~172.7 MiB (66.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 152.9 MiB/~172.7 MiB (66.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 153.2 MiB/~172.7 MiB (66.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 153.4 MiB/~172.7 MiB (66.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 153.7 MiB/~172.7 MiB (66.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 153.9 MiB/~172.7 MiB (66.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 154.2 MiB/~172.7 MiB (66.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 154.4 MiB/~172.7 MiB (66.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 154.7 MiB/~172.7 MiB (66.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 154.9 MiB/~172.7 MiB (66.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 155.2 MiB/~172.7 MiB (66.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 155.4 MiB/~172.7 MiB (66.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 155.7 MiB/~172.7 MiB (67.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 155.9 MiB/~172.7 MiB (67.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 156.2 MiB/~172.7 MiB (67.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 156.4 MiB/~172.7 MiB (67.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 156.7 MiB/~172.7 MiB (67.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 156.9 MiB/~172.7 MiB (67.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 157.2 MiB/~172.7 MiB (67.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 157.4 MiB/~172.7 MiB (67.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 157.7 MiB/~172.7 MiB (67.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 157.9 MiB/~172.7 MiB (67.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 158.2 MiB/~172.7 MiB (67.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 158.4 MiB/~172.7 MiB (67.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 158.7 MiB/~172.7 MiB (67.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 158.9 MiB/~172.7 MiB (67.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 159.2 MiB/~172.7 MiB (67.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 159.4 MiB/~172.7 MiB (67.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 159.7 MiB/~172.7 MiB (68.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 159.9 MiB/~172.7 MiB (67.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 160.2 MiB/~172.7 MiB (68.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 160.4 MiB/~172.7 MiB (68.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 160.7 MiB/~172.7 MiB (68.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 160.9 MiB/~172.7 MiB (68.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 161.2 MiB/~172.7 MiB (68.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 161.4 MiB/~172.7 MiB (68.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 161.7 MiB/~172.7 MiB (68.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 161.9 MiB/~172.7 MiB (68.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 162.2 MiB/~172.7 MiB (68.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 162.4 MiB/~172.7 MiB (68.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 162.7 MiB/~172.7 MiB (68.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 162.9 MiB/~172.7 MiB (68.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 163.2 MiB/~172.7 MiB (69.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 163.4 MiB/~172.7 MiB (69.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 163.7 MiB/~172.7 MiB (69.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 163.9 MiB/~172.7 MiB (69.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 164.2 MiB/~172.7 MiB (69.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 164.4 MiB/~172.7 MiB (69.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 164.7 MiB/~172.7 MiB (69.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 164.9 MiB/~172.7 MiB (69.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 165.2 MiB/~172.7 MiB (69.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 165.4 MiB/~172.7 MiB (69.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 165.7 MiB/~172.7 MiB (69.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 165.9 MiB/~172.7 MiB (69.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 166.2 MiB/~172.7 MiB (69.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 166.4 MiB/~172.7 MiB (69.2 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 166.7 MiB/~172.7 MiB (69.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 166.9 MiB/~172.7 MiB (69.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 167.2 MiB/~172.7 MiB (69.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 167.4 MiB/~172.7 MiB (69.5 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 167.7 MiB/~172.7 MiB (69.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 167.9 MiB/~172.7 MiB (69.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 168.2 MiB/~172.7 MiB (69.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 168.4 MiB/~172.7 MiB (69.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 168.7 MiB/~172.7 MiB (69.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 168.9 MiB/~172.7 MiB (69.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 169.2 MiB/~172.7 MiB (69.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 169.4 MiB/~172.7 MiB (69.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 169.7 MiB/~172.7 MiB (69.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 169.9 MiB/~172.7 MiB (69.0 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 170.2 MiB/~172.7 MiB (68.8 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 170.4 MiB/~172.7 MiB (68.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 170.7 MiB/~172.7 MiB (68.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 170.9 MiB/~172.7 MiB (68.3 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 171.2 MiB/~172.7 MiB (68.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 171.4 MiB/~172.7 MiB (67.7 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 171.7 MiB/~172.7 MiB (67.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 171.9 MiB/~172.7 MiB (67.4 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 172.2 MiB/~172.7 MiB (66.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 172.4 MiB/~172.7 MiB (66.9 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 172.7 MiB/~172.7 MiB (65.9 MiB/s) with ~1 file(s) remaining (calculating...)
download: s3://openneuro.org/ds003965/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_space-T1w_desc-preproc_bold.nii.gz to ../../../../../../NI-edu-data/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_space-T1w_desc-preproc_bold.nii.gz
Completed 172.7 MiB/~172.7 MiB (65.9 MiB/s) with ~0 file(s) remaining (calculating...)
Completed 8.1 KiB/~8.1 KiB (48.5 KiB/s) with ~1 file(s) remaining (calculating...)
download: s3://openneuro.org/ds003965/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_space-T1w_desc-brain_mask.nii.gz to ../../../../../../NI-edu-data/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_space-T1w_desc-brain_mask.nii.gz
Completed 8.1 KiB/~8.1 KiB (48.5 KiB/s) with ~0 file(s) remaining (calculating...)
Completed 256.0 KiB/~1.2 MiB (646.2 KiB/s) with ~1 file(s) remaining (calculating...)
Completed 512.0 KiB/~1.2 MiB (1.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 768.0 KiB/~1.2 MiB (1.6 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.0 MiB/~1.2 MiB (2.1 MiB/s) with ~1 file(s) remaining (calculating...)
Completed 1.2 MiB/~1.2 MiB (2.5 MiB/s) with ~1 file(s) remaining (calculating...)
download: s3://openneuro.org/ds003965/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_desc-confounds_timeseries.tsv to ../../../../../../NI-edu-data/derivatives/fmriprep/sub-03/ses-1/func/sub-03_ses-1_task-face_run-1_desc-confounds_timeseries.tsv
Completed 1.2 MiB/~1.2 MiB (2.5 MiB/s) with ~0 file(s) remaining (calculating...)
Done!
As you can see, it contains both “raw” (not-preprocessed) subject data (e.g., sub-03) and derivatives, which include Fmriprep-preprocessed data:
fprep_sub03 = os.path.join(data_dir, 'derivatives', 'fmriprep', 'sub-03')
print("Contents derivatives/fmriprep/sub-03:", os.listdir(fprep_sub03))
Contents derivatives/fmriprep/sub-03: ['ses-1']
There is preprocessed anatomical data and session-specific functional data:
fprep_sub03_ses1_func = os.path.join(fprep_sub03, 'ses-1', 'func')
contents = sorted(os.listdir(fprep_sub03_ses1_func))
print("Contents ses-1/func:", '\n'.join(contents))
Contents ses-1/func: sub-03_ses-1_task-face_run-1_desc-confounds_timeseries.tsv
sub-03_ses-1_task-face_run-1_space-T1w_desc-brain_mask.nii.gz
sub-03_ses-1_task-face_run-1_space-T1w_desc-preproc_bold.nii.gz
That’s a lot of data! Importantly, we will only use the “face” data (“task-face”) in T1 space (“space-T1w”), meaning that this dat has not been normalized to a common template (unlike the “task-MNI152NLin2009cAsym” data). Here, we’ll only analyze the first run (“run-1”) data. Let’s define the functional data, the associated functional brain mask (a binary image indicating which voxels are brain and which are not), and the file with timepoint-by-timepoint confounds (such as motion parameters):
func = os.path.join(fprep_sub03_ses1_func, 'sub-03_ses-1_task-face_run-1_space-T1w_desc-preproc_bold.nii.gz')
# Notice this neat little trick: we use the string method "replace" to define
# the functional brain mask
func_mask = func.replace('desc-preproc_bold', 'desc-brain_mask')
confs = os.path.join(fprep_sub03_ses1_func, 'sub-03_ses-1_task-face_run-1_desc-confounds_timeseries.tsv')
confs_df = pd.read_csv(confs, sep='\t')
confs_df
| global_signal | global_signal_derivative1 | global_signal_derivative1_power2 | global_signal_power2 | csf | csf_derivative1 | csf_derivative1_power2 | csf_power2 | white_matter | white_matter_derivative1 | ... | rot_x_derivative1_power2 | rot_y | rot_y_derivative1 | rot_y_derivative1_power2 | rot_y_power2 | rot_z | rot_z_derivative1 | rot_z_power2 | rot_z_derivative1_power2 | motion_outlier00 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 32452.228653 | NaN | NaN | 1.053147e+09 | 56448.645321 | NaN | NaN | 3.186450e+09 | 33477.742348 | NaN | ... | NaN | -0.000291 | NaN | NaN | 8.450358e-08 | 0.000421 | NaN | 1.770558e-07 | NaN | 0.0 |
| 1 | 32374.326829 | -77.901823 | 6068.694064 | 1.048097e+09 | 55903.557212 | -545.088109 | 297121.046798 | 3.125208e+09 | 33461.938656 | -15.803692 | ... | 5.203235e-46 | 0.000048 | 3.383386e-04 | 1.144730e-07 | 2.269913e-09 | 0.000000 | -0.000421 | 0.000000e+00 | 1.770558e-07 | 0.0 |
| 2 | 32328.138891 | -46.187938 | 2133.325610 | 1.045109e+09 | 55694.677005 | -208.880207 | 43630.940942 | 3.101897e+09 | 33447.470231 | -14.468426 | ... | 1.588104e-08 | 0.000048 | -4.410000e-08 | 1.944810e-15 | 2.265712e-09 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000e+00 | 0.0 |
| 3 | 32310.910024 | -17.228868 | 296.833887 | 1.043995e+09 | 55575.853868 | -118.823136 | 14118.937749 | 3.088676e+09 | 33432.562277 | -14.907954 | ... | 4.992468e-07 | 0.000490 | 4.422145e-04 | 1.955537e-07 | 2.399178e-07 | 0.000000 | 0.000000 | 0.000000e+00 | 0.000000e+00 | 0.0 |
| 4 | 32294.584213 | -16.325811 | 266.532092 | 1.042940e+09 | 55408.908249 | -166.945619 | 27870.839776 | 3.070147e+09 | 33414.449996 | -18.112281 | ... | 1.071489e-07 | -0.000084 | -5.736183e-04 | 3.290380e-07 | 7.023161e-09 | 0.000170 | 0.000170 | 2.889184e-08 | 2.889184e-08 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 337 | 31946.939473 | -20.991637 | 440.648839 | 1.020607e+09 | 55087.811985 | -49.086685 | 2409.502635 | 3.034667e+09 | 33105.711432 | -29.471095 | ... | 5.920900e-08 | 0.000089 | -2.001220e-04 | 4.004881e-08 | 7.944692e-09 | -0.000059 | -0.000192 | 3.490033e-09 | 3.705336e-08 | 0.0 |
| 338 | 31950.066021 | 3.126548 | 9.775302 | 1.020807e+09 | 55027.153585 | -60.658401 | 3679.441558 | 3.027988e+09 | 33103.520451 | -2.190981 | ... | 1.318576e-07 | 0.000089 | 0.000000e+00 | 0.000000e+00 | 7.944692e-09 | 0.000034 | 0.000093 | 1.148071e-09 | 8.641506e-09 | 0.0 |
| 339 | 31944.702633 | -5.363388 | 28.765934 | 1.020464e+09 | 55133.790131 | 106.636546 | 11371.352943 | 3.039735e+09 | 33008.779629 | -94.740822 | ... | 4.723668e-08 | 0.000089 | 0.000000e+00 | 0.000000e+00 | 7.944692e-09 | -0.000059 | -0.000093 | 3.490033e-09 | 8.641506e-09 | 0.0 |
| 340 | 31947.495584 | 2.792952 | 7.800578 | 1.020642e+09 | 55189.106597 | 55.316466 | 3059.911431 | 3.045837e+09 | 33106.108555 | 97.328926 | ... | 1.424617e-07 | 0.000280 | 1.908810e-04 | 3.643556e-08 | 7.840784e-08 | 0.000052 | 0.000112 | 2.749849e-09 | 1.243571e-08 | 0.0 |
| 341 | 31939.892753 | -7.602831 | 57.803039 | 1.020157e+09 | 55111.799336 | -77.307261 | 5976.412621 | 3.037310e+09 | 33035.758455 | -70.350100 | ... | 5.988788e-10 | 0.000400 | 1.198090e-04 | 1.435420e-08 | 1.598584e-07 | 0.000000 | -0.000052 | 0.000000e+00 | 2.749849e-09 | 0.0 |
342 rows × 231 columns
Finally, we need the events-file with onsets, durations, and trial-types for this particular run:
events = os.path.join(data_dir, 'sub-03', 'ses-1', 'func', 'sub-03_ses-1_task-face_run-1_events.tsv')
events_df = pd.read_csv(events, sep='\t')
events_df = events_df.query("trial_type != 'rating' and trial_type != 'response'") # don't need this
# Oops, Nilearn doesn't accept trial_type values that start with a number, so
# let's prepend 'tt_' to it!
events_df['trial_type'] = 'tt_' + events_df['trial_type']
Now, it’s up to you to use this data to fit an LSA model!
Remove all columns except “onset”, “duration”, and “trial_type”. You should end up with a DataFrame with 40 rows and 3 columns. You can check this with the .shape attribute of the DataFrame. (Note that, technically, you could model the reponse and rating-related events as well! For now, we’ll exclude them.) Name this filtered DataFrame events_df_filt.
You also need to select specific columns from the confounds DataFrame, as we don’t want to include all confounds! For now, include only the motion parameters (trans_x, trans_y, trans_z, rot_x, rot_y, rot_z). You should end up with a confounds DataFrame with 342 rows and 6 columns. Name this filtered DataFrame confs_df_filt.
''' Implement your ToDo here. '''
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
assert(events_df_filt.shape == (40, 3))
assert(events_df_filt.columns.tolist() == ['onset', 'duration', 'trial_type'])
assert(confs_df_filt.shape == (confs_df.shape[0], 6))
assert(all('trans' in col or 'rot' in col for col in confs_df_filt.columns))
print("Well done!")
Set the correct TR (this is 0.7)
Set the slice time reference to 0.5
Set the mask image to the one we defined before
Use a “glover” HRF
Use a “cosine” drift model with a cutoff of 0.01 Hz
Do not apply any smoothing
Set minimize_memory to true
Use an “ols” noise model
Then, fit your model using the functional data (func), filtered confounds, and filtered events we defined before.
''' Implement your ToDo here. '''
# Ignore the DeprecationWarning!
from nilearn.glm.first_level import FirstLevelModel
# YOUR CODE HERE
raise NotImplementedError()
""" Tests the above ToDo. """
from niedu.tests.nipa.week_1 import test_lsa_flm
test_lsa_flm(flm_todo, func_mask, func, events_df_filt, confs_df_filt)
Note that the compute_contrast method returns the “unmasked” results (i.e., from all voxels). Make sure that, for each trial, you mask the results using the func_mask variable and the apply_mask function from Nilearn. Save these masked results (which should be patterns of 66298 voxels) for each trial. After the loop, stack all results in a 2D array with the different trials in different rows and the (flattened) voxels in columns. This array should be of shape 40 (trials) by 65643 (nr. of masked voxels). The variable name of this array should be R_todo.
''' Implement your ToDo here. '''
from nilearn.masking import apply_mask
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_lsa_R
test_lsa_R(R_todo, events_df_filt, flm_todo, func_mask)
Dealing with trial correlations#
When working with single-trial experimental designs (such as the LSA designs discussed previously), one often occurring problem is correlation between trial predictors and their resulting estimates. Trial correlations in such designs occur when the inter-stimulus interval (ISI) is sufficiently short such that trial predictors overlap and thus correlate. This, in turn, leads to relatively unstable (high-variance) pattern estimates and, as we will see later in this section, trial patterns that correlate with each other (which is sometimes called pattern drift).
This is also the case in our data from the NI-edu dataset. In the “face” task, stimuli were presented for 1.25 seconds, followed by a 3.75 ISI, which causes a slightly positive correlation between a given trial (\(i\)) and the next trial (\(i + 1\)) and a slightly negative correlation between the trial after that (\(i + 2\)). We’ll show this below by visualizing the correlation matrix of the design matrix:
dm_todo = pd.read_csv('dm_todo.tsv', sep='\t')
dm_todo = dm_todo.iloc[:, :40]
fig, ax = plt.subplots(figsize=(8, 8))
# Slightly exaggerate by setting the limits to (-.3, .3)
mapp = ax.imshow(dm_todo.corr(), vmin=-0.3, vmax=0.3)
# Some styling
ax.set_xticks(range(dm_todo.shape[1]))
ax.set_xticklabels(dm_todo.columns, rotation=90)
ax.set_yticks(range(dm_todo.shape[1]))
ax.set_yticklabels(dm_todo.columns)
cbar = plt.colorbar(mapp, shrink=0.825)
cbar.ax.set_ylabel('Correlation', fontsize=15, rotation=-90)
plt.show()
YOUR ANSWER HERE
The trial-by-trial correlation structure in the design leads to a trial-by-trial correlation structure in the estimated patterns as well (as explained by Soch et al., 2020). We show this below by computing and visualizing the \(N \times N\) correlation matrix of the patterns:
# Load in R_todo if you didn't manage to do the
# previous ToDo
R_todo = np.load('R_todo.npy')
# Compute the NxN correlation matrix
R_corr = np.corrcoef(R_todo)
fig, ax = plt.subplots(figsize=(8, 8))
mapp = ax.imshow(R_corr, vmin=-1, vmax=1)
# Some styling
ax.set_xticks(range(dm_todo.shape[1]))
ax.set_xticklabels(dm_todo.columns, rotation=90)
ax.set_yticks(range(dm_todo.shape[1]))
ax.set_yticklabels(dm_todo.columns)
cbar = plt.colorbar(mapp, shrink=0.825)
cbar.ax.set_ylabel('Correlation', fontsize=15, rotation=-90)
plt.show()
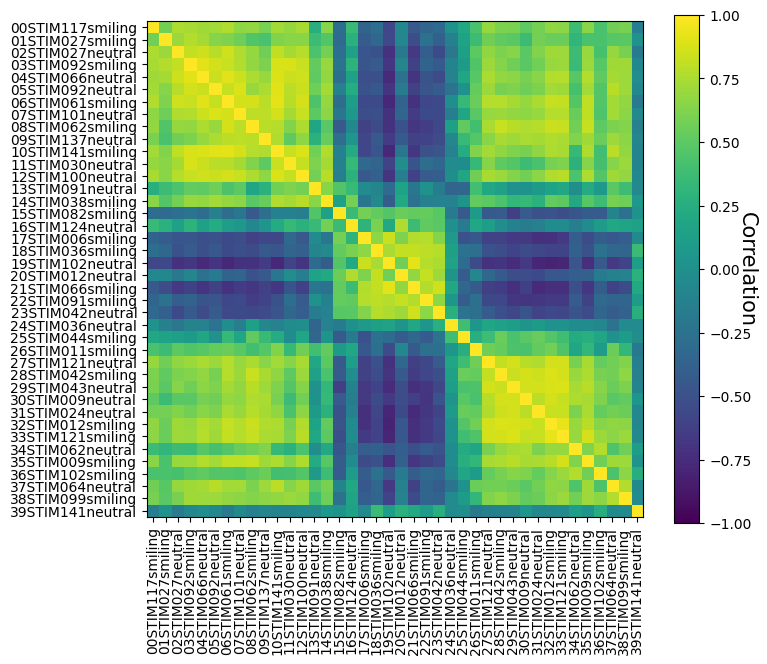
This correlation structure across trials poses a problem for representational similarity analysis (the topic of week 3) especially. Although this issue is still debated and far from solved, in this section we highlight two possible solutions to this problem: least-squares separate designs and temporal “uncorrelation”.
Least-squares separate (LSS)#
The least-squares separate LSS) design is a slight modifcation of the LSA design (Mumford et al., 2014). In LSS, you fit a separate model per trial. Each model contains one regressor for the trial that you want to estimate and, for each condition in your experimental design (in case of a categorical design), another regressor containing all other trials.
So, suppose you have a run with 30 trials across 3 conditions (A, B, and C); using an LSS approach, you’d fit 30 different models, each containing four regressors (one for the single trial, one for all (other) trials of condition A, one for all (other) trials of condition B, and one for all (other) trials of condition C). The apparent upside of this is that it strongly reduces the collinearity of trials close in time, which in turn makes the trial parameters more efficient to estimate.
YOUR ANSWER HERE
We’ll show this for our example data. It’s a bit complicated (and not necessarily the best/fastest/clearest way), but the comments will explain what it’s doing. Essentially, what we’re doing, for each trial, is to extract that regressor for a standard LSA design and, for each condition, create a single regressor by summing all single-trial regressors from that condition together.
# First, well make a standard LSA design matrix
lsa_dm = make_first_level_design_matrix(
frame_times=t_fmri, # we defined this earlier for interpolation!
events=events_sim,
hrf_model='glover',
drift_model=None # assume data is already high-pass filtered
)
# Then, we will loop across trials, making a single GLM
lss_dms = [] # we'll store the design matrices here
# Do not include last column, the intercept, in the loop
for i, col in enumerate(lsa_dm.columns[:-1]):
# Extract the single-trial predictor
single_trial_reg = lsa_dm.loc[:, col]
# Now, we need to create a predictor per condition
# (one for A, one for B). We'll store these in "other_regs"
other_regs = []
# Loop across unique conditions ("A" and "B")
for con in np.unique(conditions):
# Which columns belong to the current condition?
idx = con == np.array(conditions)
# Make sure NOT to include the trial we're currently estimating!
idx[i] = False
# Also, exclude the intercept (last column)
idx = np.append(idx, False)
# Now, extract all N-1 regressors
con_regs = lsa_dm.loc[:, idx]
# And sum them together!
# This creates a single predictor for the current
# condition
con_reg_all = con_regs.sum(axis=1)
# Save for later
other_regs.append(con_reg_all)
# Concatenate the condition regressors (one of A, one for B)
other_regs = pd.concat(other_regs, axis=1)
# Concatenate the single-trial regressor and two condition regressors
this_dm = pd.concat((single_trial_reg, other_regs), axis=1)
# Add back an intercept!
this_dm.loc[:, 'intercept'] = 1
# Give it sensible column names
this_dm.columns = ['trial_to_estimate'] + list(set(conditions)) + ['intercept']
# Save for alter
lss_dms.append(this_dm)
print("We have created %i design matrices!" % len(lss_dms))
We have created 20 design matrices!
Alright, now let’s check out the first five design matrices, which should estimate the first five trials and contain 4 regressors each (one for the single trial, two for the separate conditions, and one for the intercept):
fig, axes = plt.subplots(ncols=5, figsize=(15, 10))
for i, ax in enumerate(axes.flatten()):
plot_design_matrix(lss_dms[i], ax=ax)
ax.set_title("Design for trial %i" % (i+1), fontsize=20)
plt.tight_layout()
plt.show()
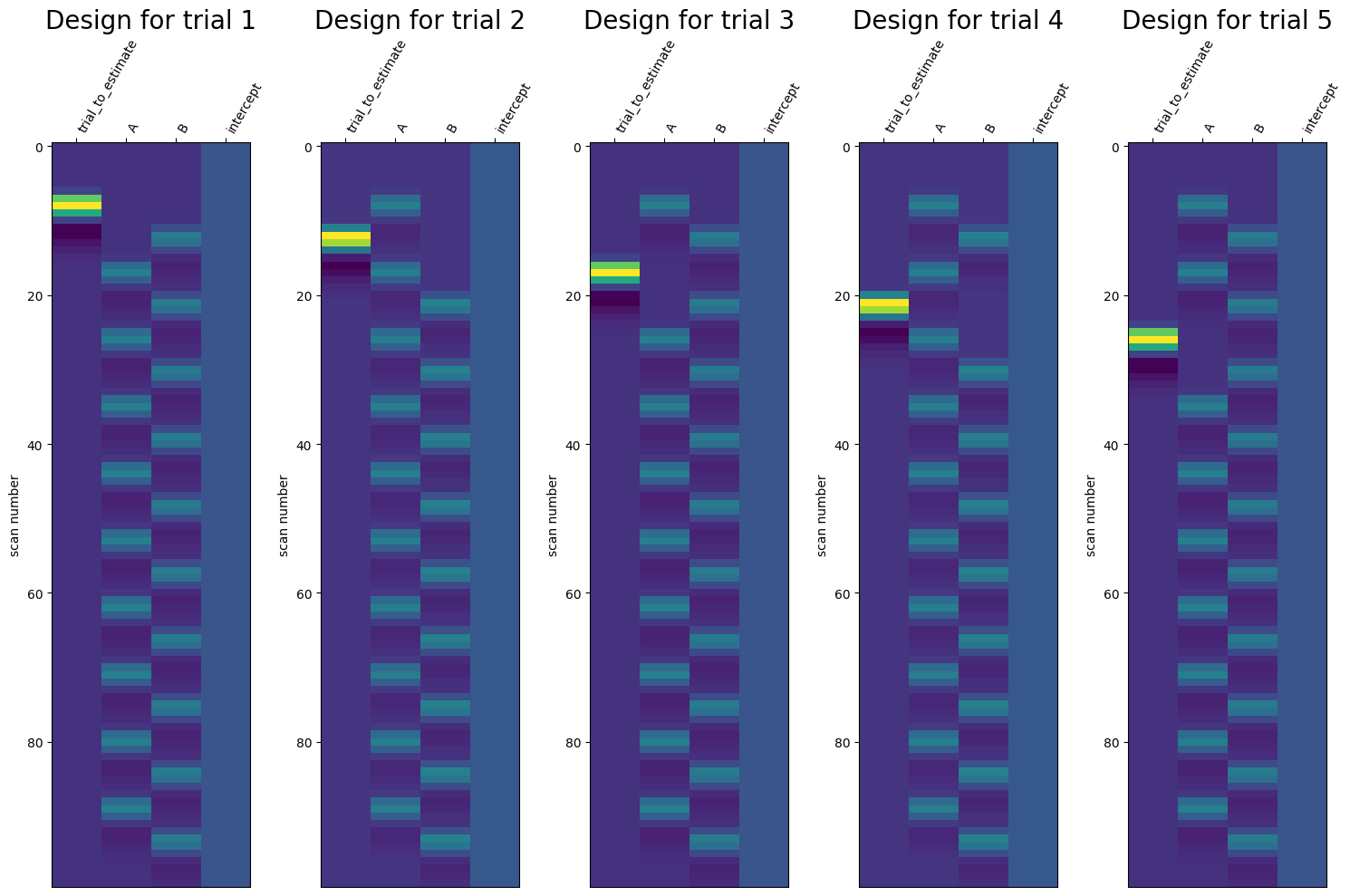
''' Implement your ToDo here. Note that we already created the LSA design matrix for you. '''
func_img = nib.load(func)
n_vol = func_img.shape[-1]
lsa_dm = make_first_level_design_matrix(
frame_times=np.linspace(0, n_vol * 0.7, num=n_vol, endpoint=False),
events=events_df_filt,
drift_model=None
)
# YOUR CODE HERE
raise NotImplementedError()
''' Tests the above ToDo. '''
from niedu.tests.nipa.week_1 import test_lss
test_lss(R_todo_lss, func, flm_todo, lsa_dm, confs_df_filt)
Temporal uncorrelation#
Another method to deal with trial-by-trial correlations is the “uncorrelation” method by Soch and colleagues (2020). As opposed to the LSS method, the uncorrelation approach takes care of the correlation structure in the data in a post-hoc manner. It does so, in essence, by “removing” the correlations in the data that are due to the correlations in the design in a way that is similar to what prewhitening does in generalized least squares.
Formally, the “uncorrelated” patterns (\(R_{\mathrm{unc}}\)) are estimated by (matrix) multiplying the square root (\(^{\frac{1}{2}}\)) of covariance matrix of the LSA design matrix (\(X^{T}X\)) with the patterns (\(R\)):
Here, \((X^{T}X)^{\frac{1}{2}}\) represents the “whitening” matrix which uncorrelates the patterns. Let’s implement this in code. Note that we can use the sqrtm function from the scipy.linalg package to take the square root of a matrix:
from scipy.linalg import sqrtm
# Design matrix
X = dm_todo.to_numpy()
R_unc = sqrtm(X.T @ X) @ R_todo
This uncorrelation technique is something we’ll see again in week 3 when we’ll talk about multivariate noise normalization!
Alright, that was it for this lab! We have covered the basics of experimental design and pattern estimation techniques for fMRI data. Note that there are many other (more advanced) things related to pattern estimation that we haven’t discussed, such as standardization of patterns, multivariate noise normalization, hyperalignment, etc. etc. Some of these topics will be discussed in week 2 (decoding) or week 3 (RSA).