{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Spatial preprocessing\n",
"*If you haven't gone through the `temporal_preprocessing.ipynb` notebook, please do so first!*\n",
"\n",
"In the previous notebook, we've looked at how to temporally preprocess our signal through high-pass filtering, prewhitening, and nuisance regression. Importantly, these operations are *performed on the timeseries of each voxel separately*! Essentially, given our 4D fMRI data ($X \\times Y \\times Z \\times T$), temporal filtering as we discussed here is only applied to the fourth dimension (the time-dimension, $T$).\n",
"\n",
"In addition to these temporal operations, there are several spatial operations performed on (f)MRI data, including spatial smoothing (a form of filtering), distortion correction, and spatial registration/resampling, which are discussed in this notebook.\n",
"\n",
"**What you'll learn**: after this lab, you'll ...\n",
"\n",
"- explain the necessity of motion correction and the advantage of motion regression\n",
"- know how to implement the concepts above in Python\n",
"\n",
"**Estimated time needed to complete**: 4-6 hours"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# import some functionality\n",
"import os.path as op\n",
"import numpy as np\n",
"import nibabel as nib\n",
"import matplotlib.pyplot as plt\n",
"from scipy.ndimage import gaussian_filter"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Spatial filtering (blurring/smoothing)\n",
"Spatial filtering refers to operations applied to the *spatial* dimensions ($X$, $Y$, and $Z$) of our 4D data. The most common spatial filtering operation — spatial smoothing — is usually implemented using a \"3D gaussian (low-pass) smoothing kernel\". Sounds familiar? Well, it should, because it's essentially the same type of filter as we used for our temporal high-pass filter! Only this time, it's not a 1-dimensional gaussian (\"kernel\") that does the high-pass filtering, but it's a 3-dimensional gaussian that does *low-pass* filtering. Just like the temporal gaussian-weighted running line smoother is applied across time, we apply the 3D gaussian across space (i.e., the 3 spatial dimensions, $X$, $Y$, and $Z$). The figure below schematically visualized the process\\*:\n",
"\n",
"\n",
"\n",
"(Note that we show the spatial data in 2D, simply because it's easier to visualize, but in reality this is always 3D!)\n",
"\n",
"In fact, because both (high-pass) temporal filtering and (low-pass) spatial filtering in most fMRI applications depend on the same \"gaussian filtering\" principle, we can even use the same Python function: `gaussian_filter`! However, as we mentioned before, spatial smoothing in fMRI is used as a *low-pass filter*, which means that the (spatial!) frequencies *higher* than a certain cutoff are filtered out, while the (spatial!) frequencies *lower* than this cut-off are *passed*. Therefore, we don't need to subtract the output from the `gaussian_filter` function from the (spatial) data! (If we'd would that, than we're effectively high-pass filtering the data!)\n",
"\n",
"---\n",
"\\* 3D gaussian figure from Philipp Klaus."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
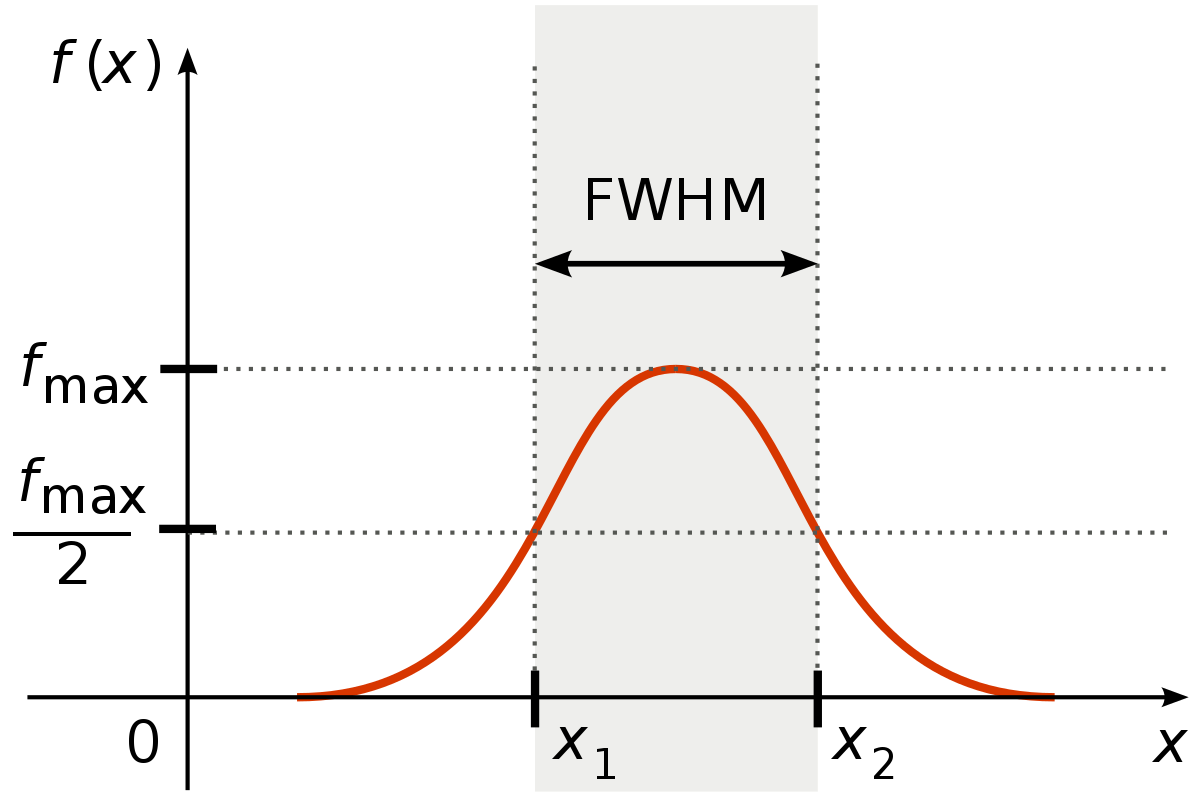
"Before we go on and demonstrate smoothing on fMRI data, we need to determine the sigma of our (3D) gaussian kernel that we'll use to smooth the data. Annoyingly, smoothing kernels in the fMRI literature (and software packages!) are usually not reported in terms of sigma, but as \"full-width half maximum\" (FWHM), which refers to the width of the gaussian at half the maximum height:\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"For example, you might read in papers something like \"We smoothed our data with a gaussian kernel with a FWHM of 3 millimeter\". So, we need to convert our desired FWHM (in millimeters) to sigma. In fact, this is the same conversion that we needed to do for our temporal Gaussian running line high-pass filter, but this time applied to the spatial domain (i.e., FWHM in mm) instead of the temporal domain (i.e., TR in seconds). We can use the same formula to convert FWHM (in mm.) to sigma: \n",
"\n",
"\\begin{align}\n",
"\\sigma_{kernel} = \\frac{\\mathrm{FWHM}_{mm}}{\\sqrt{8 \\ln{2}} \\cdot \\mathrm{voxel\\ size}_{mm}}\n",
"\\end{align}\n",
"\n",
"So, for example, if I want to smooth at FWHM = 6 mm and my voxels are 3 mm in size (assuming equal size in the three spatial dimensions, which is common), my sigma becomes:\n",
"\n",
"\\begin{align}\n",
"\\sigma_{kernel} = \\frac{6}{\\sqrt{8 \\ln{2}} \\cdot 3} \\approx 0.85\n",
"\\end{align}\n",
"\n",
"The entire conversion process is a bit annoying, but it's simply necessary due to conventions in the fMRI literature/software packages.\n",
"\n",
"Anyway, having dealt with the conversion issue, let's look at an example. We'll use the 4D fMRI data from before (the `data_4d` variable) and we'll extract a single 3D volume which we'll smooth using the `gaussian_filter` function. This particular data has a voxel-size of $6\\ mm^{3}$; given that we want to smooth at an FWHM of, let's say, 10 millimeter, we need a sigma of $\\frac{10}{\\sqrt{8 \\ln{2}} \\cdot 6} \\approx 0.7$."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"f = op.join(op.dirname(op.abspath('')), 'week_1', 'func.nii.gz')\n",
"data_4d = nib.load(f).get_fdata()\n",
"vol = data_4d[:, :, :, 20] # We'll pick the 21st volume (Python is 0-indexed, remember?)\n",
"\n",
"fwhm = 10\n",
"voxelsize = 6\n",
"\n",
"sigma = fwhm / (np.sqrt(8 * np.log(2)) * voxelsize)\n",
"smoothed_vol = gaussian_filter(vol, sigma=sigma)\n",
"\n",
"# Let's plot both the unsmoothed and smoothed volume\n",
"plt.figure(figsize=(12, 5))\n",
"plt.subplot(1, 2, 1)\n",
"plt.imshow(vol[:, :, 30], cmap='gray') # And we'll pick the 11th axial slice to visualize\n",
"plt.axis('off')\n",
"plt.title(\"Unsmoothed volume\\n\", fontsize=15)\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"plt.imshow(smoothed_vol[:, :, 30], cmap='gray')\n",
"plt.axis('off')\n",
"plt.title('Smoothed volume\\n($\\sigma = %.1f; FWHM = %s_{mm}$)' % (sigma, fwhm), fontsize=15)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (2 points): Now, in the above example we only smoothed a single volume, but in your analyses you would of course smooth all volumes in your fMRI run! (Just like with temporal filtering you need to filter the timeseries of all voxels separately.) In this ToDo, you need to loop through all (50) volumes from the data_4d variable and smooth them separately. Store the smoothed data in the already pre-allocated variable data_4d_smoothed. Use a sigma of 0.7 for the gaussian filter.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "cdf3ecb0b9be9c6c17388206df4fef17",
"grade": false,
"grade_id": "cell-6c6a67416765405d",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here\n",
"\n",
"data_4d_smoothed = np.zeros(data_4d.shape)\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "db57d1585966afd821097b436550a1c0",
"grade": true,
"grade_id": "cell-0592292dc79b7722",
"locked": true,
"points": 2,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the ToDo above '''\n",
"from niedu.tests.nii.week_4 import test_smoothing_todo \n",
"test_smoothing_todo(data_4d, data_4d_smoothed)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToThink (1 point): Since the gaussian_filter works for any $N$-dimensional array, one could argue that you don't have to loop through all volumes and apply a 3D filter, but you could equally well skip the loop and use a 4D filter straightaway. Explain (concisely) why this is a bad idea (for fMRI data).\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "28d1cf717215a33678ec31025646258a",
"grade": true,
"grade_id": "cell-8d04961478f5fde2",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Susceptibility distortion correction (SDC)\n",
"Most functional MRI sequences use a technique called \"gradient-echo echo planar imaging\" (GE-EPI), which is a relatively sensitive and well-established technique for BOLD-MRI. For reasons beyond the scope of this course, GE-EPI scans unfortunately show signs of **\"geometric distortion\"** (sometimes called susceptibility distortion) and **signal loss** in some areas of the brain. Signal loss, which is most apparent in areas with B0 (static magnetic field) inhomogeneities caused by sudden air-tissue transitions (like around the ears, earduct → brain, and the ventromedial cortex, frontal sinus → brain). Geometric distortion is most visible in the phase-encoding direction of the scan (usually posterior → anterior or left → right). These geometric distorions are usually visible as tissue \"folding\" inwards or outwards (depending on the exact phase-encoding direction, e.g., posterior → anterior or anterior → posterior). \n",
"\n",
"In the gif below, you can see where signal loss (in ventromedial cortex and around the ears, best visible in slice `z=12`) and geometric distortion is most apparent. The \"before\" image is the one *with* geometric distortion (most apparent as folding inwards of the cerebellum and frontal cortex). Hover your cursor above the image to see it changing from uncorrected (\"before\") to corrected (\"after\").\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"While there is (currently) no way to correct for signal loss, there *are* ways to correct for geometric distortion (as you can see in the gif above). Most distortion correction techniques require you to acquire additional scans that can be used to correct (or \"unwarp\") your functional MRI scans. One technique is to acquire a \"fieldmap\" scan to image the homogeneity of the magnetic field (based on two scans with slightly different TEs) which can then be used for geometric correction. Another technique, often called \"topup unwarping\" (or PEPOLAR unwarping), uses one or more volumes of a separate functional MRI scan with the opposite phase-encoding direction as your to-be-correction functional MRI scan. In the \"topup\" scan, the distortion is expected to be in the complete opposite direction as in your to-be-correction fMRI scan (e.g., inward folding of tissue where the fMRI scan would show outward folding and vice versa), which can then be used to estimate an undistorted shape (which is \"in the middle\" of the fMRI and topup scan). \n",
"\n",
"The mathematics and implementation of distortion correction is beyond the scope of this course, but we just wanted it to show you so that you're familiar with the term!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Motion correction / realignment\n",
"Participant movement during scanning arguably affects your data quality most, and should be taken care of accordingly. As such, *motion correction* (or sometimes called *motion realignment*) is an important step in any preprocessing pipeline. Motion correction makes sure that all volumes (i.e., 3D fMRI images) are spatially aligned. Before discussing motion correction in more detail, let's take a look at how a motion corrupted scan looks like. Actually, the data that we've been using so far (`data_4d`) actually has very little motion, so we're going to add some motion to it (with a custom function `add_motion_to_vols`). Then, we'll plot it volume by volume as a short movie:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from niedu.utils.nii import add_motion_to_vols, animate_volumes\n",
"\n",
"vols = add_motion_to_vols(data_4d)\n",
"animate_volumes(vols)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Rigid body registration\n",
"Motion correction aligns all volumes by picking a reference volume (usually the first or middle one) and subsequently \"moving\" all the other volumes such that they are spatially aligned with the reference volume. Specifically, motion correction uses *translation* (movement along the primary axes: left/right, up/down, front/back) and *rotation* (around the center of the image).\n",
"\n",
"\n",
"*Image from [Arcoverde Neto et al. (2014)](https://www.researchgate.net/figure/Orientation-of-the-head-in-terms-of-pitch-roll-and-yaw-movements-describing-the-three_fig1_279291928).*\n",
"\n",
"This specific transformation of the image has six parameters (translation in the X, Y, and Z direction, and rotation in the X, Y, and Z direction) and is often called a \"rigid body registration\". Given these parameters, the to-be-moved volume can be spatially resampled at the location of the reference volume.\n",
"\n",
"A rigid body registration is an example of a more general *affine registration*: a linear transformation of an image that may involve translation, rotation, scaling, and shearing. For motion correction, scaling and shearing is *not* applied."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToThink (0 points): Why do you think motion correction not use scaling and shearing transformations?\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Affine registrations\n",
"For affine registrations, the way the image should be moved is defined in the affine matrix, a $4 \\times 4$ matrix. This matrix is similar to the one we discussed in week 1, but instead of describing how each image coordinate ($i, j, k$) relates to world coordinates ($x, y, z$), the affine matrix, here, describes how the coordinates from the original (non-corrected) image related to the corrected image:\n",
"\n",
"\\begin{align}\n",
"\\begin{bmatrix} i_{corr}, j_{corr}, k_{corr}, 1 \\end{bmatrix} = A\\begin{bmatrix}\n",
" i \\\\\n",
" j \\\\\n",
" k \\\\\n",
" 1\n",
" \\end{bmatrix}\n",
"\\end{align}\n",
"\n",
"For example, suppose I have a particular affine matrix (`A_example`, below) that encodes a translation of 3 voxels downwards (superior → inferior). Then, for any coordinate $(x, y, z, 1)$, I can compute the location of the coordinate in the corrected image as follows:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"A_example = np.array([\n",
" [1, 0, 0, 0],\n",
" [0, 1, 0, 0],\n",
" [0, 0, 1, 3],\n",
" [0, 0, 0, 1]\n",
"])\n",
"\n",
"# Note that we always have to append a 1, just like in week 1\n",
"coord = np.array([0, 0, 0, 1]) # the middle of the image!\n",
"corr_coord = A_example @ coord\n",
"print(corr_coord[:3])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As expected, the affine transformation above shows us that the middle coordinate $(0, 0, 0)$ refers to the corrected coordinate $(0, 0, 3)$ after translating the image 3 voxels downwards. But how is this particular translation encoded in the affine? For translation, this is relatively straightforward. For any translation $(x, y, z)$, the affine matrix looks like:\n",
"\n",
"\\begin{align}\n",
"\\begin{bmatrix} i_{\\mathrm{trans}} & j_{\\mathrm{trans}} & k_{\\mathrm{trans}} & 1 \\end{bmatrix} =\n",
"\\begin{bmatrix}\n",
" 1 & 0 & 0 & x \\\\\n",
" 0 & 1 & 0 & y \\\\\n",
" 0 & 0 & 1 & z \\\\\n",
" 0 & 0 & 0 & 1\n",
"\\end{bmatrix}\n",
"\\begin{bmatrix}\n",
" i \\\\\n",
" j \\\\\n",
" k \\\\\n",
" 1\n",
" \\end{bmatrix}\n",
"\\end{align}\n",
"\n",
"For rotation, however, it is slightly more complicated! For rotation transformations (with rotations $x, y, z$ in radians), the affine is computed by the matrix \n",
"\n",
"\\begin{align}\n",
"\\begin{bmatrix} i_{\\mathrm{rot}} & j_{\\mathrm{rot}} & k_{\\mathrm{rot}} & 1 \\end{bmatrix} =\n",
" \\begin{bmatrix}\n",
" 1 & 0 & 0 & 0 \\\\\n",
" 0 & \\cos(x) & -\\sin(x) & 0 \\\\\n",
" 0 & \\sin(x) & \\cos(x) & 0 \\\\\n",
" 0 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
" \\begin{bmatrix}\n",
" \\cos(y) & 0 & \\sin(y) & 0 \\\\\n",
" 0 & 1 & 0 & 0 \\\\\n",
" -\\sin(y) & 0 & \\cos(y) & 0 \\\\\n",
" 0 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
" \\begin{bmatrix}\n",
" \\cos(z) & -\\sin(z) & 0 & 0 \\\\\n",
" \\sin(z) & \\cos(z) & 0 & 0 \\\\\n",
" 0 & 0 & 1 & 0 \\\\\n",
" 0 & 0 & 0 & 1\n",
" \\end{bmatrix}\n",
" \\begin{bmatrix}\n",
" i \\\\\n",
" j \\\\\n",
" k \\\\\n",
" 1\n",
" \\end{bmatrix}\n",
"\\end{align}\n",
"\n",
"As you can see, rotations are actually encoded in the affine matrix as the result of matrix multiplication of the the separate x, y, and z rotation matrices. Don't worry, you don't have to program this rotation-to-affine operation. Using a custom function (`get_rotation_matrix`), let's take a look at what the affine matrix would look like for a rotation of 45 degrees in every direction:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def get_rotation_matrix(x=0, y=0, z=0):\n",
" \"\"\" Computes the rotation matrix.\n",
" \n",
" Parameters\n",
" ----------\n",
" x : float\n",
" Rotation in the x (first) dimension in degrees\n",
" y : float\n",
" Rotation in the y (second) dimension in degrees\n",
" z : float\n",
" Rotation in the z (third) dimension in degrees\n",
" \n",
" Returns\n",
" -------\n",
" rot_mat : numpy ndarray\n",
" Numpy array of shape 4 x 4\n",
" \"\"\"\n",
" \n",
" x = np.deg2rad(x)\n",
" y = np.deg2rad(y)\n",
" z = np.deg2rad(z)\n",
" \n",
" rot_roll = np.array([\n",
" [1, 0, 0, 0],\n",
" [0, np.cos(x), -np.sin(x), 0],\n",
" [0, np.sin(x), np.cos(x), 0],\n",
" [0, 0, 0, 1]\n",
" ])\n",
"\n",
" rot_pitch = np.array([\n",
" [np.cos(y), 0, np.sin(y), 0],\n",
" [0, 1, 0, 0],\n",
" [-np.sin(y), 0, np.cos(y), 0],\n",
" [0, 0, 0, 1]\n",
" ])\n",
"\n",
" rot_yaw = np.array([\n",
" [np.cos(z), -np.sin(z), 0, 0],\n",
" [np.sin(z), np.cos(z), 0, 0],\n",
" [0, 0, 1, 0],\n",
" [0, 0, 0, 1]\n",
" ])\n",
"\n",
" rot_mat = rot_roll @ rot_pitch @ rot_yaw\n",
" return rot_mat\n",
" \n",
" \n",
"A_rot = get_rotation_matrix(x=45, y=45, z=45)\n",
"print(A_rot)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, if we want to combine both rotations and translations, we multiply the translation matrix ($T$) with our rotation matrix ($R = R_{x}R_{y}R_{z}$):\n",
"\n",
"\\begin{align}\n",
"A = TR\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Below, we also define a function to get the translation matrix. Now, suppose I want to rotate my image with 45 degrees in the z-direction and translate my image with 10 voxels in the x-direction and 5 voxels in the y-direction. Calculate the corresponding affine matrix, and store this in a variable named affine_todo.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "6c07100da2e9de8f9cb37785879bc48d",
"grade": false,
"grade_id": "cell-ae387d34dc0502cf",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"def get_translation_matrix(x=0, y=0, z=0):\n",
" \"\"\" Computes the translation matrix.\n",
" \n",
" Parameters\n",
" ----------\n",
" x : float\n",
" Translation in the x (first) dimension in voxels\n",
" y : float\n",
" Rotation in the y (second) dimension in voxels\n",
" z : float\n",
" Rotation in the z (third) dimension in voxels\n",
" \n",
" Returns\n",
" -------\n",
" trans_mat : numpy ndarray\n",
" Numpy array of shape 4 x 4\n",
" \"\"\"\n",
" \n",
" trans_mat = np.eye(4)\n",
" trans_mat[:, -1] = [x, y, z, 1]\n",
" return trans_mat\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "750344e241b739c94342ad07f96c6f78",
"grade": true,
"grade_id": "cell-2fe012448a3f390d",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_4 import test_affine_todo\n",
"test_affine_todo(affine_todo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, we're not going to discuss the intricacies of how to actually resample an image given a particular affine. Instead, we defined a function called `resample_image` that resamples an image given a particular translation and rotation matrix. It's a bit more complicated than we discussed so far, but you get the idea."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from scipy.ndimage import affine_transform\n",
"\n",
"def resample_image(image, trans_mat, rot_mat):\n",
" \"\"\" Resamples an image given a translation and rotation matrix.\n",
" \n",
" Parameters\n",
" ----------\n",
" image : numpy array\n",
" A 3D numpy array with image data\n",
" trans_mat : numpy array\n",
" A numpy array of shape 4 x 4\n",
" rot_mat : numpy array\n",
" A numpy array of shape 4 x 4\n",
" \n",
" Returns\n",
" -------\n",
" image_reg : numpy array\n",
" A transformed 3D numpy array\n",
" \"\"\"\n",
" \n",
" # We need to rotate around the origin, not (0, 0), so\n",
" # add a \"center\" translation\n",
" center = np.eye(4)\n",
" center[:3, -1] = np.array(image.shape) // 2 - 0.5\n",
" A = center @ trans_mat @ rot_mat @ np.linalg.inv(center)\n",
" \n",
" # affine_transform does \"pull\" resampling by default, so\n",
" # we need the inverse of A\n",
" image_corr = affine_transform(image, matrix=np.linalg.inv(A))\n",
" \n",
" return image_corr"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (0 points): Try out different transformations of an actual brain image by changing the arguments given to get_translation_matrix and get_rotation_matrix. You can also change the axis (PLOT_AXIS) and slice number (SLICE_IDX) that is plotted.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"trans_mat = get_translation_matrix(5, 5, 0)\n",
"rot_mat = get_rotation_matrix(0, 0, 40)\n",
"\n",
"vols = data_4d\n",
"VOL = vols[:, :, :, 0]\n",
"PLOT_AXIS = 2\n",
"SLICE_IDX = 20\n",
"\n",
"plt.figure(figsize=(10, 5))\n",
"plt.subplot(1, 2, 1)\n",
"plt.imshow(np.take(VOL, SLICE_IDX, PLOT_AXIS).T, origin='lower', cmap='gray')\n",
"plt.axis('off')\n",
"plt.title('Original image', fontsize=20)\n",
"\n",
"# Resample\n",
"vol_res = resample_image(VOL, trans_mat, rot_mat)\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"plt.imshow(np.take(vol_res, SLICE_IDX, PLOT_AXIS).T, origin='lower', cmap='gray')\n",
"plt.axis('off')\n",
"plt.title('Transformed image', fontsize=20)\n",
"\n",
"plt.tight_layout()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, suppose that we want to align two volumes with each other. How would we go about it? Visually, it's quite hard to assess whether a particular affine matrix works well. In practice, most neuroimaging software packages use automatic algorithms that try to find a affine matrix that *minimizes some cost function*. In other words, it defines a function to evaluate the mismatch (or cost) of the alignment of two volumes given an affine matrix, and then it tries to minimize this function by (in a smart way) trying out different rotation and translation parameters.\n",
"\n",
"One cost function that is often used for rigid body registration is \"least squares\", which is defined as the sum over the squared (voxel-wise, $v$) differences between the reference image (sometimes called the \"fixed\" image) and the realigned image (sometimes called the \"moving\" image):\n",
"\n",
"\\begin{align}\n",
"\\mathrm{cost}_{LS} = \\sum_{v}(\\mathrm{fixed}_{v} - \\mathrm{moving}_{v})^2\n",
"\\end{align}"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Define a function named least_squares_cost below, that takes two input parameters — fixed and moving (both 3D numpy arrays) — and outputs the least-squares cost. Note: you don't need a for loop!\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "236d6f2a40befad8c3b7ed90e0cce5af",
"grade": false,
"grade_id": "cell-a1efe673673187ef",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "68bbd35a5c099121da0bd4f98a158c9c",
"grade": true,
"grade_id": "cell-9db862292e2766d3",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"\"\"\" Tests the above ToDo \"\"\"\n",
"fixed = np.ones((10, 10, 10))\n",
"moving = np.zeros((10, 10, 10))\n",
"\n",
"np.testing.assert_almost_equal(least_squares_cost(fixed, moving), 1000)\n",
"\n",
"fixed = np.arange(1000).reshape((10, 10, 10))\n",
"moving = fixed[::-1]\n",
"np.testing.assert_almost_equal(least_squares_cost(fixed, moving), 330000000)\n",
"\n",
"moving = np.roll(fixed.ravel(), 1).reshape((10, 10, 10))\n",
"np.testing.assert_almost_equal(least_squares_cost(fixed, moving), 999000)\n",
"\n",
"print(\"Well done!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): For this ToDo, you are going to be the optimizer! Below, we have loaded two (brain) images: fixed and moving. Use the resample_image function to translate/rotate the moving image. Make sure you name the output (i.e., the transformed volume) moved. This is then plotted on top of the reference volume to give you an idea of how well your transformation worked. Keep doing this until you're satisfied.\n",
" \n",
"Hint 1: you need rotation in the z dimension and translation in the x and y dimension.
\n",
"Hint 2: rotation is counter clockwise (if you define negative rotation, e.g. -20, it will be rotated clockwise).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "b46fab32c20ce50a99d1360dc0d660bd",
"grade": true,
"grade_id": "cell-367a4f3bd6f89c4a",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"with np.load('moco_todo.npz') as moco_data:\n",
" moving = moco_data['moving']\n",
" fixed = moco_data['fixed']\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()\n",
"\n",
"### Plotting starts here\n",
"# Only works if you've defined a variable named 'moved'\n",
"# Do not change the code below\n",
"plt.figure(figsize=(10, 10))\n",
"plt.imshow(fixed[:, :, 25].T, origin='lower', cmap='gray')\n",
"moved4plot = np.ma.masked_where(moved < 2, moved)\n",
"plt.imshow(moved4plot[:, :, 25].T, origin='lower', alpha=0.8)\n",
"plt.axis('off')\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Anatomical realignment/registration and normalization\n",
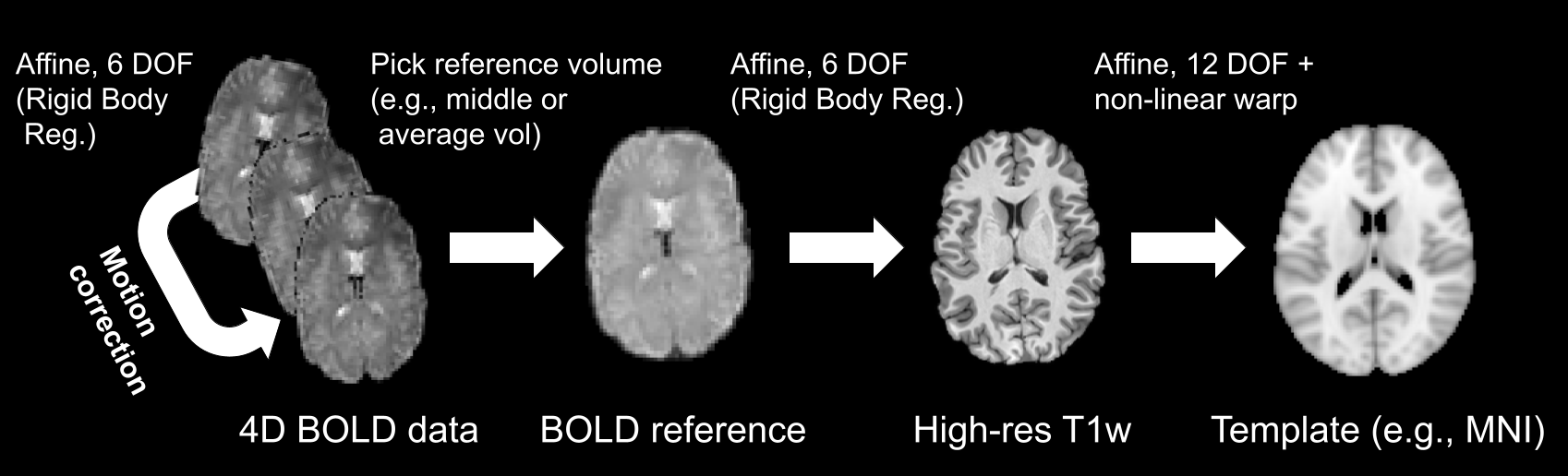
"So far, we discussed how to register volumes to a reference volume using rigid body registrations (with a six parameter affine) in the context of motion correction. This is, however, only the first step in the complete registration protocol of (most) studies. If your goal is, in the end, to perform some kind of group analysis (in which you pool together data from multiple subjects), you want to make sure that each voxel (at location $(X, Y, Z)$) is in (roughly) the same location in the brain. The problem is that people's brains differ quite a bit in terms of anatomy! Therefore, you need to register (transform) your subject-level (functional) data to some kind of common template. This process is often done in two stages: first, you compute a registration from (a reference volume of) your functional data (\"moving\") to your anatomical data (your high-resolution T1-weighted scan; \"fixed\"), and second you compute a registration from your anatomical data (\"moving\") to a common template (\"fixed\"). Then, you can register your functional data to the common template by sequentially applying the first and second stage registration parameters. This is visualized in the figure below.\n",
"\n",
"\n",
"\n",
"In the figure above, you can see that the first stage (BOLD → T1w) uses the same registration protocol as we used with motion-correction: an affine transformation with 6 parameters (translation and rotation in 3 directions; a \"rigid body registration\"). The second stage (T1w → template) also uses an affine transformation, but this time with 12 parameters. In addition to the 6 rigid body registration parameters, a 12 parameter affine (sometimes reffered to as an affine with 12 degrees-of-freedom, DOF) also includes global scaling in 3 directions (i.e., making the brain bigger of smaller) and shearing in 3 directions (i.e., \"stretching\" in 3 directions). These extra parameters attempt to overcome the anatomical differences between the individual subjects' brains and the template. \n",
"\n",
"However, only a 12 DOF affine is usually not sufficient for proper alignment. Therfore, most neuroimaging software packages also offer the option to apply a non-linear registration step (\"warping\") *on top of the 12 DOF affine registration*. Instead of globally transforming your \"moving\" volume (i.e., the transformation applies to each voxel equally), non-linear registrations allow for *local* transformations (i.e., some voxels might be transformed \"more\" than others). Usually, the combination of an initial 12 DOF affine and a non-linear (\"warping\") registration operation lead to a proper alignment of the subject's anatomical volume and the template."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToThink (2 points): When we discussed motion correction, we used the \"least squares\" cost function to optimize our rigid body registration parameters. Is it a good idea to use this cost function for the BOLD → T1w registration procedure? And for our initial T1w → template registration procedure? Argue for both cases why (not).\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "226571d4d9116e0ef8c14c1217c4977d",
"grade": true,
"grade_id": "cell-10b71c1f875e6d4d",
"locked": false,
"points": 2,
"schema_version": 3,
"solution": true,
"task": false
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Motion filtering\n",
"Even after motion realignment, your data is still 'contaminated' by motion. This is because movement itself influences the measured activity. For example, suppose that you measure a single voxel in someone's brain; then, this person moves his/her head 2 centimeters. Now, we can do motion realigment to make sure we measure the same voxel before and after the movement, but *this does not change the fact that this particular voxel was originally measured at two different locations*. It could be that after the movement, the voxel was actually a little bit closer to the headcoil, which results in a (slight) increase in signal compared to before the movement (this is also known as \"spin history effects\").\n",
"\n",
"Ideally, you want to account for these interactions between motion and the measured activity. One way to do this is through \"motion filtering\", of which one popular approach is to simply add the 6 realignment parameters (rotation and translation in 3 directions) to the design-matrix ($X$)! In other words, we treat the motion realignment parameters as \"nuisance regressors\" that are aimed to explain activity that is related to motion. Realize that this is, thus, as temporal preprocessing step (which we discuss here instead of the previous notebook because we needed to explain motion correction first).\n",
"\n",
"Alright, let's load some realigment parameters (6 in total) from an fMRI run of 200 volumes. We'll plot them below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"\"\"\" This data has been motion-corrected using the FSL tool 'MCFLIRT', which outputs a file\n",
"ending in *.par that contains the 6 motion parameters (rotation/translation in 3 directions each).\n",
"We'll load in this file and plot these motion parameters. \"\"\"\n",
"\n",
"motion_params = np.loadtxt('func_motion_pars_new.txt')\n",
"rotation_params = motion_params[:, :3]\n",
"translation_params = motion_params[:, 3:]\n",
"\n",
"plt.figure(figsize=(15, 7))\n",
"plt.subplot(2, 1, 1)\n",
"plt.title('Rotation', fontsize=25)\n",
"plt.plot(rotation_params)\n",
"plt.xlim(0, motion_params.shape[0])\n",
"plt.legend(['x', 'y', 'z'], fontsize=15)\n",
"plt.ylabel('Rotation in radians', fontsize=15)\n",
"plt.grid()\n",
"\n",
"plt.subplot(2, 1, 2)\n",
"plt.title('Translation', fontsize=25)\n",
"plt.plot(translation_params)\n",
"plt.legend(['x', 'y', 'z'], fontsize=15)\n",
"plt.ylabel('Translation in mm', fontsize=15)\n",
"plt.xlim(0, motion_params.shape[0])\n",
"plt.xlabel('Time (TR)', fontsize=15)\n",
"plt.grid()\n",
"\n",
"plt.tight_layout()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"So, is this good data or not? In general, you could say that higher values (in either translation or rotation) are worse. That said, from the translation and rotation parameters alone it is hard to judge whether the participant moved *too* much, partly because we're dealing with 6 parameter traces here. One way to make this decision process a little easier is to convert these parameters to a single \"framewise displacement\" (FD) trace. FD aims to represent \"bulk motion\" and is a summary statistic of motion that combines all motion parameters into a single metric. It is calculated as follows:\n",
"\n",
"\\begin{align}\n",
"FD_{t} = |r(\\mathrm{rot}_{tx} - \\mathrm{rot}_{(t-1)x})| + |r(\\mathrm{rot}_{ty} - \\mathrm{rot}_{(t-1)y})| + |r(\\mathrm{rot}_{tz} - \\mathrm{rot}_{(t-1)z})| + |\\mathrm{trans}_{xt} - \\mathrm{trans}_{x(t-1)}| + |\\mathrm{trans}_{yt} - \\mathrm{trans}_{y(t-1)}| + |\\mathrm{trans}_{zt} - \\mathrm{trans}_{z(t-1)}|\n",
"\\end{align}\n",
"\n",
"where $|x|$ means the absolute value of $x$ and $r$ stands for a predefined radius in millimeters (which is usually taken to be 50). So, basically it is a sum across the absolute successive differences ($x_{t} - x_{t-1}$) of parameter traces."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (0 points; optional): Calculate the FD trace corresponding to the motion parameters in the motion_params variable. Assume a radius of 50. Store the result in a variable named fd_trace. Note that, just like with the RMSSD, the first value is undefined (because at $t=0$, there is no $t-1$). Therefore, prepend a 0 to your FD trace.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "02724321e95398bcd307079c29d0e8da",
"grade": false,
"grade_id": "cell-851337eba26429e2",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement the optional ToDo here\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "0653e006b851f7afc941a5fa3508564d",
"grade": true,
"grade_id": "cell-df4b286bad8da0ad",
"locked": true,
"points": 0,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_4 import test_fd_calc\n",
"test_fd_calc(motion_params, fd_trace)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (0 points): Looking at the plots above (before the optional ToDo), can you deduce which volume was used as a reference volume? You can also use the motion_params variable to find out.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As said in the beginning of this section, motion parameters (translation/rotation in 3 dimensions) are used as nuisance regressors in subject-level analyses. The reason for this is that, even after motion correction, the actual movement may have influenced the signal intensity through \"spin-history effects\", which occurs when a voxel is excited by an RF pulse slightly earlier/later due to movement (i.e., it may have moved up or down one slice), which changes how much T1 relaxation occurs (which affect the signal intensity; read more [here](http://imaging.mrc-cbu.cam.ac.uk/imaging/CommonArtefacts)).\n",
"\n",
"There are two ways to go about this, which are not mutually exclusive. The most common way (in task-based fMRI) is to add the six motion parameters (rotation/translation in three directions) to your design. Any variance of your signal that covaries with (one or more of) these motion parameters will be accounted for (and will thus *not* end up in your noise term)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (0 points; optional): Sometimes, in addition to the original six rigid body registration parameters, people add the lag-1 shiften parameters (i.e., $t-1$) to their design, as well as the squares (i.e., $x^{2}$) of those twelve regressors, yielding a set of 24 nuisance regressors (sometimes called the \"Friston24\" set). Calculate this extended set of motion parameters and store it in a variable named friston24. Hint: because (again) the timepoint $t-1$ is not defined at $t=0$, prepend a row of zeros to the lag-1 shifted parameters. \n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "e79b924fe4247d7a4301e8060010fac7",
"grade": false,
"grade_id": "cell-7cefa2c24e24556a",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "31a1ff1b281d2cf53a602e5438f476a7",
"grade": true,
"grade_id": "cell-dfeca80192f08c70",
"locked": true,
"points": 0,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_4 import test_friston24 \n",
"test_friston24(motion_params, friston24)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Apart from directly adding the (extended) motion parameters to your design, you can also perform \"motion scrubbing\". Motion scrubbing is usually performed in resting-state analyses and is conceptually very similar to the \"despiking\" we did earlier. With motion scrubbing, you usually set a predefined threshold for your FD trace (for example 1 mm) and any timepoint above this threshold will be \"scrubbed out\". This is done by defining a separate regressor for each timepoint above the threshold containing all zeros except for the above-threshold timepoint, which contains a zero (just like we did with despiking). Sometimes, even the timepoint before and/or after the \"bad\" timepoint are additionally added to the design matrix. As this course focuses mostly on task-based fMRI analyses, we won't discuss motion scrubbing any further (but if you want to know more about the different motion correction strategies, we recommend the following article: [Power et al., 2015](https://www.sciencedirect.com/science/article/pii/S1053811914008702))."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (2 points)\n",
" \n",
"For this ToDo, you have to compare two models and the resulting (normalized) effects (t-values): a model *without* the six motion parameters and a model *with* the six motion parameters. You should use the motion_params variable which we defined earlier as your motion parameters.\n",
"\n",
"We provide you with a design-matrix (X) with an intercept and a single stimulus-predictor and the signal of a single voxel (sig). Calculate the t-value for the contrast of the predictor-of-interest against baseline for both the original design-matrix (only intercept + predictor-of-interest; store this in a variable named tval_simple)\n",
"and the design-matrix extended with the six motion parameters (which thus has 8 predictors; store this in a variable named tval_ext).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First, we'll load the data\n",
"with np.load('data_motion_filtering.npz') as data_last_todo:\n",
" X = data_last_todo['X']\n",
" sig = data_last_todo['sig']\n",
"\n",
"print(\"Shape of original X: %s\" % (X.shape,))\n",
"print(\"Shape of signal: %s\" % (sig.shape,))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "3c734336b757682760a60c432fc43761",
"grade": false,
"grade_id": "cell-bc72faf7a5efe723",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"\"\"\" Implement the ToDo here. \"\"\"\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "51000231df575f619c2fc3335e86bcb4",
"grade": true,
"grade_id": "cell-b96ab79b7be0d9b5",
"locked": true,
"points": 2,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_4 import test_tvals_motion \n",
"test_tvals_motion(X, sig, motion_params, tval_simple, tval_ext)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (2 points): If you did the above ToDo correctly, you should have found that the $t$-value of the extended model (with motion parameters) is actually smaller than the simple model (without motion parameters) ... What caused the t-value of this predictor to become smaller when the motion-parameters were included in your design-matrix? Inspect the different elements of the $t$-value formula carefully.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "496ef198454b0c40d1226a9ff13f39dd",
"grade": true,
"grade_id": "cell-a0a6ef6b1921850b",
"locked": false,
"points": 2,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Alright, that's it for preprocessing! If you want to know more about a preprocessing software package that we particularly like, check out the next (optional) notebook about [Fmriprep](https://fmriprep.readthedocs.io/) (`fmriprep.ipynb`)!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Tip!\n",
" Before handing in your notebooks, we recommend restarting your kernel (Kernel → Restart & Clear Ouput) and running all your cells again (manually, or by Cell → Run all). By running all your cells one by one (from \"top\" to \"bottom\" of the notebook), you may spot potential errors that are caused by accidentally overwriting your variables or running your cells out of order (e.g., defining the variable 'x' in cell 28 which you then use in cell 15).\n",
"
"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": true,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 4
}