{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Design of experiments\n",
"This notebook is about the statistical considerations related to fMRI experimental design. Make sure you do the other lab (`glm_part2_inference.ipynb`) first!\n",
"\n",
"Experimental designs for fMRI studies come in different flavors, depending on what hypotheses you have about the phenomenon of interest and how you manipulate this. Apart from the different types of experimental designs (e.g., subtractive, factorial, parametric), there are a couple of general recommendations w.r.t. experimental design that can optimize the chance of finding positive results, which will be discussed in this notebook as well. These recommendations have to do with the specific ordering and timing of the events in your experiment. For example, suppose you show images of cats (condition: \"C\") and dogs (condition: \"D\") to subjects in the scanner, and you're interested if the brain responds differently to images of dogs compared to images of cats. What ordering (\"CCCCDDDD\" or \"CDCDCDCD\" or \"CCDCDDCD\"?) and timing (how long should I wait to present another stimulus?) of the stimuli will yield the best (here: highest) effect possible, and why? \n",
"\n",
"**What you'll learn**: after this lab, you'll ...\n",
"\n",
"- understand what 'design variance' is and how it relates to 'efficiency'\n",
"- understand the effect of design variance *t*-values\n",
"- know how to calculate design variance in Python\n",
"\n",
"**Estimated time needed to complete**: 4-6 hours
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# First some imports\n",
"import numpy as np\n",
"import matplotlib.pyplot as plt\n",
"from nilearn.glm.first_level.hemodynamic_models import glover_hrf\n",
"from scipy.stats import pearsonr"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Types of designs: factorial and parametric designs\n",
"In the previous tutorial ('the GLM: part 2'), we discussed contrasts at length and how to use contrast-vectors to specify simple hypotheses (e.g., happy faces > sad faces). The contrast-vectors from last week's lab were examples of either simple contrasts-against-baseline ($H_{0}: \\beta = 0$) or examples of *subtractive designs* (also called categorical designs; e.g., $H_{0}: \\beta_{1} - \\beta_{2} = 0$). There are, however, more types of designs possible, like *factorial* and *parametric* designs. In this first section, we'll discuss these two designs shortly and have you implement GLMs to test hypotheses forwarded by these designs."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Factorial designs\n",
"Factorial designs are designs in which each event (e.g., stimulus) may be represented by a combination of different conditions. For example, you could show images of squares and circles (condition 1: shape) which may be either green or red (condition 2: color). See the image below for a visualization of these conditions and the associated contrasts.\n",
"\n",
"\n",
"\n",
"Before we'll explain this figure in more detail, let's generate some data. We'll assume that the TR is 1 second and that all onsets are always syncronized with the TR (so there won't be onsets at, e.g., 10.295 seconds). This way, we can ignore the downsampling issue. We'll convolve the data with an HRF already and plot the design matrix below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from niedu.utils.nii import simulate_signal\n",
"\n",
"exp_length = 160\n",
"TR = 1\n",
"xmax = exp_length // TR\n",
"\n",
"y, X = simulate_signal(\n",
" onsets=np.array(\n",
" [0, 40, 80, 120, # red squares\n",
" 10, 50, 90, 130, # red circles\n",
" 20, 60, 100, 140, # green squares\n",
" 30, 70, 110, 150] # green circles\n",
" ),\n",
" conditions=['rq'] * 4 + ['rc'] * 4 + ['gs'] * 4 + ['gc'] * 4,\n",
" TR=TR,\n",
" duration=exp_length,\n",
" icept=0,\n",
" params_canon=[1, 2, 3, 4],\n",
" rnd_seed=42,\n",
" plot=False\n",
")\n",
"\n",
"X = X[:, :5]\n",
"\n",
"plt.figure(figsize=(15, 5))\n",
"plt.plot(X[:, 1], c='r', ls='--')\n",
"plt.plot(X[:, 2], c='r')\n",
"plt.plot(X[:, 3], c='g', ls='--')\n",
"plt.plot(X[:, 4], c='g')\n",
"plt.xlim(0, xmax)\n",
"plt.ylim(-0.3, 1.2)\n",
"plt.xlabel('Time (seconds/TRs)', fontsize=20)\n",
"plt.ylabel('Activity (A.U.)', fontsize=20)\n",
"plt.legend(['red squares', 'red circles', 'green squares', 'green circles'], frameon=False)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We have also the time series of a (hypothetical) fMRI voxel, loaded and plotted below:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"plt.figure(figsize=(15, 5))\n",
"plt.plot(y)\n",
"plt.xlim(0, xmax)\n",
"plt.axhline(0, ls='--', c='k', lw=0.75)\n",
"plt.xlabel('Time (seconds/TRs)', fontsize=20)\n",
"plt.ylabel('Activity (A.U.)', fontsize=20)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (2 points): Time to refresh your memory on how to implement the GLM! Run linear regression with the design specified above (i.e., the X variable). Store the resulting parameters (i.e., the \"betas\") in a new variable named betas_todo. Check whether the design already includes an intercept!\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "ef921d43f298c585701b003003ddcf99",
"grade": false,
"grade_id": "cell-20f169584ebaa863",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"from numpy.linalg import inv\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "82b65952879c1699382bd4b9864478a1",
"grade": true,
"grade_id": "cell-8b35137bdd094866",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo'''\n",
"from niedu.tests.nii.week_3 import test_glm_refresher\n",
"test_glm_refresher(X, y, betas_todo)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Alright, now, from the figure above, you can see there are many different contrast possible! First of all, we can test for *main effects*: these are effects of a single condition, collapsing over the other(s). For example, testing whether red stimuli lead to different activity levels than green stimuli (regardless of shape) would be a test of a main effect. Technically, main effects within factorial designs are tested with F-tests, which are undirectional tests, which mean that they test for *any* difference between conditions (e.g., *either* that red > green *or* green > red). However, this rarely happens in cognitive neuroscience, as most hypotheses are directional (e.g., red > green), so we'll focus on those types of hypotheses in factorial designs here."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Define a contrast-vector below (which should be a numpy array with 5 values) with the name cvec_red_green that would test the hypothesis that red stimuli evoke more activity than green stimuli (regardless of shape).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "c362cc147781a7826fadb1474071ed2e",
"grade": false,
"grade_id": "cell-28f514117c039ed6",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "228bc871b725151eda635feca3478904",
"grade": true,
"grade_id": "cell-f1bb0e0d8e990703",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo '''\n",
"from niedu.tests.nii.week_3 import test_red_larger_than_green\n",
"test_red_larger_than_green(cvec_red_green)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Another hypothesis that you could have is that circles evoke more activity than squares (regardless of color). Define a contrast-vector below (which should be a numpy array with 5 values) with the name cvec_circle_square that would test this hypothesis.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "6bc8b44f5a533196c0067c0446b78a83",
"grade": false,
"grade_id": "cell-13ea4e3306fd2963",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "80208053e157944dcd7b5c2beb8c1ab7",
"grade": true,
"grade_id": "cell-a1949576f701741f",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo '''\n",
"from niedu.tests.nii.week_3 import test_circles_larger_than_squares\n",
"test_circles_larger_than_squares(cvec_circle_square)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Alright, these (directional) main effects should be familiar as they don't differ very much from those that you saw last week. However, factorial designs are unique in that they, additionally, can test for *interactions* between conditions. Again, technically, (undirectional) F-tests should be used, but again, these are rarely used in cognitive neuroscience. \n",
"\n",
"So, let's define a directional interaction effect. Suppose that, for some reason, I believe that red stimuli evoke more activity than green stimuli, but more so for circles than for squares. In other words:\n",
"\n",
"\\begin{align}\n",
"(\\hat{\\beta}_{\\mathrm{red, circle}} - \\hat{\\beta}_{\\mathrm{green,circle}}) > (\\hat{\\beta}_{\\mathrm{red, square}} - \\hat{\\beta}_{\\mathrm{green,square}})\n",
"\\end{align}\n",
"\n",
"It turns out, there is a very nice trick to figure out the corresponding contrast for this interaction: you can simply (elementwise) multiply the contrast vector for \"red > green\" and the contrast vector for \"circle > squares\"!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Define a contrast vector below, named cvec_interaction, that tests the hypothesis that red stimuli evoke more activity than green stimuli, but more so for circles than for squares (i.e., the one from the example above).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "b55593068032121082fe196844ac2b4a",
"grade": false,
"grade_id": "cell-b2faeb3e5b078be7",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "3fac21f52dc406b4e7f50225cfe6d617",
"grade": true,
"grade_id": "cell-5ff3d3950181cc08",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo '''\n",
"from niedu.tests.nii.week_3 import test_interaction\n",
"test_interaction(cvec_interaction)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's practice working with interactions once more."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Define a contrast vector below, named cvec_interaction2, that tests the hypothesis that squares evoke more activity than circles, but less so for green stimuli than for red stimuli.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "e3538b5c5e0c2e11780686dff7062e7c",
"grade": false,
"grade_id": "cell-17a247c75e75f308",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "f46bee56bb279d7f5bcb1494b42b89b9",
"grade": true,
"grade_id": "cell-21adb16fb699f117",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo '''\n",
"from niedu.tests.nii.week_3 import test_interaction2\n",
"test_interaction2(cvec_interaction2)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Parametric designs\n",
"So far, we have discussed only designs with conditions that are categorical, such as \"male vs. female faces\" and \"circles vs. squares\". The independent variables in your experimental design, however, do not *have* to be categorical! They can be continuous or ordinal, meaning that a particular variable might have different values (or \"weights\") across trials. Designs involving continuously varying properties are often called *parametric designs* or *parametric modulation*.\n",
"\n",
"In parametric designs, we assume that our design affects the voxel response in two ways:\n",
"1. An \"unmodulated\" response (a response to the stimulus/task *independent* of parametric value);\n",
"2. A parametric modulation of the response\n",
"\n",
"To make this more tangible, let's consider an example. Suppose that we have fMRI data from a reward-study. On every trial in this experiment, trials would start with a word \"guess\" on the screen for 1 second. Then, participants had to guess a number between 1 and 10 (which they indicated using an MRI-compatible button box). Before the experiment started, participants were told that the closer they were to the \"correct\" number (which was predetermined by the experimenter for every trial), the larger the reward they would get: 1 euro when their guess was correct and 10 cents less for every number that they were off (e.g., when the \"correct\" number was 7 and they would guess 5, then they'd receive 80 eurocents). After the participant's response and a inter-stimulus interval of 4 seconds, participants would see the amount they won on the screen.\n",
"\n",
"\n",
"\n",
"One hypothesis you might be interested in is whether there are voxels/brain regions which response is modulated by the reward magnitude (e.g., higher activity for larger rewards, or vice versa). Before we go on, let's create some (hypothetical) experimental data. Suppose that the experiment lasted 10 minutes and contained 30 trials with varying reward magnitude, and fMRI was acquired with a TR of 1 second and onsets of the reward presentations were synchronized with the TR (again, while this is not very realistic, this obviates the need for up/downsampling)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"np.random.seed(42)\n",
"exp_time = 60 * 10 # i.e., 14 minutes in seconds\n",
"n_trials = 30\n",
"reward_onsets = np.arange(4, exp_time, exp_time / n_trials).astype(int)\n",
"print(\"Number of trials: %i\" % reward_onsets.size)\n",
"\n",
"reward_magnitudes = np.random.randint(1, 11, size=reward_onsets.size) / 10\n",
"\n",
"plt.figure(figsize=(15, 5))\n",
"plt.plot(reward_magnitudes, marker='o')\n",
"plt.xlim(-1, reward_magnitudes.size)\n",
"plt.ylim(0, 1.1)\n",
"plt.xlabel('Trial number, 0-%i (NOT TIME)' % n_trials, fontsize=20)\n",
"plt.ylabel('Reward (in euro)', fontsize=20)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, in non-parametric designs, we would create regressors with zeros everywhere and ones at the onset of stimuli (or whatever we think will impact the fMRI data). However, in parametric designs, we create two regressors for every parametric modulation: one for the unmodulated response and one for the modulated response.\n",
"\n",
"Let's start with the unmodulated response. This predictor is created like we did before: convolving a stick predictor with an HRF:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"hrf = glover_hrf(tr=1, oversampling=1)\n",
"\n",
"x_unmod = np.zeros(exp_time)\n",
"x_unmod[reward_onsets] = 1\n",
"x_unmod = np.convolve(x_unmod, hrf)[:exp_time]\n",
"\n",
"plt.figure(figsize=(15, 5))\n",
"plt.plot(x_unmod)\n",
"plt.xlim(0, exp_time)\n",
"plt.xlabel('Time (sec./vols)', fontsize=20)\n",
"plt.ylabel('Activation (A.U.)', fontsize=20)\n",
"plt.title('Unmodulated regressor', fontsize=25)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, the parametrically modulated regressor is created as follows: instead of creating an initial array with zeros and *ones* at indices corresponding to the reward onset, we use the (mean-subtracted) *reward magnitude*. It is important to subtract the mean from the parametric modulation values, because this will \"decorrelate\" the modulated regressor from the unmodulated regressor (such that the modulated regressor explains only variance that is due to modulation of the response, not the common response towards the stimulus/task). In other words, subtracting the mean from the parametric regressor *orthogonalises* the parametric regressor with respect to the unmodulated regressor.\n",
"\n",
"Then, the predictor is again convolved with the HRF to create the final modulated predictor."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"
Tip: Check out
this excellent paper by Mumford and colleagues (2015), which discusses orthogonalization in fMRI designs and when it is (in)appropriate.
This video also nicely explains orthogonalization in the context of parametric modulation analyses.\n",
"
\n",
" ToDo (1 point): Subtract the mean from the parametric modulation values (reward_magnitudes) and save this in a new variable named reward_magnitudes_ms (note: no for-loop necessary!). Now, create a new zeros-filled predictor, and set the values corresponding to the reward onsets to the mean-subtract reward magnitudes. Then, convolve the predictor with the HRF (use the variable hrf defined earlier). Make sure to trim off the excess values. Store the result in a variable named x_mod. Also plot the modulated regressor.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "48ab63f43d5c098ed1bb92aa1a118998",
"grade": false,
"grade_id": "cell-ee6830a4436305ec",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Implement your ToDo here. '''\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "333f9f9ad8e7faf8fe6c6e9df001e917",
"grade": true,
"grade_id": "cell-b4dc7a2b41866a6a",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_3 import test_parametric_modulation\n",
"test_parametric_modulation(reward_onsets, reward_magnitudes, exp_time, hrf, x_mod)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (1 point): Now, stack an intercept, the unmodulated regressor, and the modulated regressor in a single design matrix (with three columns; you might have to create a singleton axis with np.newaxis!). Make sure the order of the columns is as follows: intercept, unmodulated regressor, modulated regressor. Then, run linear regression with this design matrix on the variable y_reward_signal below. Save the parameters in a variable named betas_reward.\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "4c0f77556e738762bf62e7391d56209e",
"grade": false,
"grade_id": "cell-ce2890389562d424",
"locked": false,
"schema_version": 3,
"solution": true,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here\n",
"y_reward_signal = np.load('y_reward_signal.npy')\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "1768a9082344f7697256f4098a1d1cb9",
"grade": true,
"grade_id": "cell-6f233eb8638678e9",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false,
"task": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the ToDo above. '''\n",
"from niedu.tests.nii.week_3 import test_betas_reward\n",
"\n",
"test_betas_reward(y_reward_signal, x_mod, x_unmod, icept, betas_reward)\n",
"print(\"Well done!\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToThink (1 point): Interpret the direction of the effect of the unmodulated and modulated predictors. How does this voxel respond to the reward events?\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "112c640da1a7fc59c673d34002849dbd",
"grade": true,
"grade_id": "cell-6f586715624208c2",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true,
"task": false
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Design variance/efficiency\n",
"Alright, hopefully you now know how to design contrasts for factorial and parameteric designs! This section has a slightly different focus, namely the mathematics behind design variance and efficiency! Remember that we wouldn't tell you what \"design variance\" was in the previous two GLM tutorials? Well, this week we're going to discuss and explain it *extensively*! Before we delve into this topic, let's first recap the (conceptual) formula for the *t*-value from last week (the relevance of this will become clear shortly).\n",
"\n",
"Last week, you learned about the GLM and how to apply it to fMRI data to find out how much influence each predictor in your design has on the signal of a voxel. Crucially, you learned that you shouldn't look at raw beta-parameters to infer the effect of predictors, but that you should look at *normalized beta-parameters* — the **_t_-value**. Remember the formula for the *t*-value for a given contrast ($c$)?\n",
"\n",
"\\begin{align}\n",
"t_{\\mathbf{c}\\hat{\\beta}} = \\frac{\\mathrm{effect}}{\\sqrt{\\mathrm{noise \\cdot design\\ variance}}} = \\frac{\\mathbf{c}\\hat{\\beta}}{\\sqrt{\\frac{SSE}{\\mathrm{DF}} \\cdot \\mathrm{design\\ variance}}}\n",
"\\end{align}\n",
"\n",
"The formula for the *t*-value embodies the concept that the statistics you (should) care about, *t*-values, depend both on the **effect** (sometimes confusingly called the \"signal\"; $\\hat{\\beta}$), the **noise** ($\\hat{\\sigma}^{2} = \\frac{SSE}{\\mathrm{DF}}$), and the **\"design variance\"**.\n",
"\n",
"So, to find optimal (i.e. largest) *t*-values, we should try to optimize both the effect of our predictors (i.e. the betas), try to minimize the errors ($\\hat{\\sigma}^2$), and try to minimize the design variance of our model. In this lab, we'll shortly discuss the \"effect\" component ($\\hat{\\beta}$) and thereafter we'll discuss in detail the \"design variance\" part. We won't discuss the \"noise\" part, as this will be the topic of next week (preprocessing)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Optimizing \"effects\"\n",
"\n",
"#### Psychological factors\n",
"As discussed above, the \"effect\" part of the conceptual formula for the t-statistic refers to the $\\beta$-parameter in the statistical formula. It may sound weird to try to \"optimize\" your effect, because there is no way to magically acquire a better/stronger effect from your data, right? (Well, apart from using a better/stronger MRI-scanner.) Actually, don't forget that the effect you're measuring is coming from the brain of a *human* beings (your subjects)! There are real and important psychological influences that affect the strength of your signal, and thus influence eventually the size of your $\\beta$-parameter. \n",
"\n",
"So, what are these psychological influences? Well, think about inattention/boredom, anxiety, sleepiness (don't underestimate how many subjects fall asleep in the scanner!), and subjects not understanding your task. As an extreme example: suppose you're showing your subject some visual stimuli in order to measure the effect of some visual property (e.g., object color) in the visual cortex. Imagine that your subject finds the task so boring that he/she falls asleep; the $\\beta$-parameters in this scenario are going to be *much* lower than when the subject wouldn't have fallen asleep, of course! Sure, this is an extreme (but not uncommon!) example, but it shows the potential influence of psychological factors on the \"effect\" you're measuring in your data!\n",
"\n",
"In short, when designing an experiment, you want to continually ask yourself: \"Are subjects really doing/thinking the way I want them to?\", and consequently: \"Am I really measuring what I think I'm measuring?\" \n",
"\n",
"(The effect of psychological aspects on the measured effect is thoroughly explained in the video [Psychological principles in experimental design](https://www.youtube.com/watch?v=lwy2k8YQ-cM) from Tor Wager, which you can also find on Canvas.)\n",
"\n",
"#### Design factors\n",
"Apart from taking psychological factors into account when designing your experiment, there are also design-technical factors that influence the (potential) strength of your signal: using blocked designs. We will, however, discuss this topic in a later section, because you need a better understanding of another part of the conceptual *t*-value formula first: design variance."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Optimizing design variance\n",
"So, last week we talked quite a bit about this mysterious term \"design variance\" and we promised to discuss it the next week. That's exactly what we're going to do now. As we shortly explained last week, *design variance is the part of the standard error caused by the design-matrix ($X$)*. Importantly, design variance is closely related to the *efficiency* of the design matrix ($X$), i.e., efficiency is the inverse of design variance:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{efficiency} = \\frac{1}{\\mathrm{design\\ variance}}\n",
"\\end{align}\n",
"\n",
"This term, efficiency, will be important in the rest of this notebook. \n",
"\n",
"As these terms are inversely related, high design variance means low efficiency (which we don't want) and low design variance means high efficiency (which we want). Phrased differently, high design variance means that your design-matrix is (relatively) *inefficient* for our goal to measure significant effects (i.e., high *t*-values). But, as you might have noticed, this definition is kind of circular. What causes low design variance (high efficiency), or: what constitutes an efficient design?\n",
"\n",
"Basicially, two factors contribute to an efficient design:\n",
"1. The predictors in your design should have **high variance** (i.e. they should vary a lot relative to their mean)\n",
"2. The predictors should **not** have **high covariance** (i.e. they should not correlate between each other a lot)\n",
"\n",
"In general, for any **contrast between two $\\beta$-parameters corresponding to predictor $j$ and $k$**, we can define their design variance as follows\\*:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{design\\ variance}_{j,k} = \\frac{1}{\\mathrm{var}[X_{j}] + \\mathrm{var}[X_{k}] - 2\\cdot \\mathrm{cov}[X_{j}, X_{k}]}\n",
"\\end{align}\n",
"\n",
"As such, efficiency for this contrast would the inverse:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{efficiency}_{j,k} = \\mathrm{var}[X_{j}] + \\mathrm{var}[X_{k}] - 2\\cdot \\mathrm{cov}[X_{j}, X_{k}]\n",
"\\end{align}\n",
"\n",
"As you can see, design variance thus depends on the variance of the predictors *and* the covariance between predictors. Note that this formulation only applies to contrasts involving more than one parameter. For **contrasts against baseline, in which only one parameter is tested (e.g. predictor $j$)**, there is only one variance term (the other variance term and the covariance term are dropped out):\n",
"\n",
"\\begin{align}\n",
"\\mathrm{design\\ variance}_{j} = \\frac{1}{\\mathrm{var}[X_{j}]}\n",
"\\end{align}\n",
"\n",
"It is of course kind of annoying to have two different definitions (and computations) of design variance, which depend on whether you want to test a parameter against baseline or against another parameter. Therefore, people usually use the vectorized computation (i.e. using matrix multiplication), which allows you to define the formula for design variance *for any contrast-vector $\\mathbf{c}$*:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{design\\ variance} = \\frac{1}{\\mathrm{var}[X_{j}] + \\mathrm{var}[X_{k}] - 2\\cdot \\mathrm{cov}[X_{j}, X_{k}]} = \\mathbf{c}(\\mathbf{X}^T\\mathbf{X})^{-1}\\mathbf{c}^{T}\n",
"\\end{align}\n",
"\n",
"While this notation, $\\mathbf{c}(\\mathbf{X}^{T}\\mathbf{X})^{-1}\\mathbf{c}$, may seem quite different than the above definitions using the $\\mathrm{var}$ and $\\mathrm{cov}$ terms, it is mathematically doing the same thing. The term $(X^{T}X)^{-1}$ represents (the inverse of) the variance-covariance matrix of the design ($X$) and **c** (contrast vector) is used only to \"extract\" the relevant variances and covariance for the particular contrast out of the entire covariance matrix of $X$.\n",
"\n",
"While appearing more complex, the advantage of the vectorized definition, however, is that it works for both contrasts against baseline (e.g. `[0, 0, 1]`) and contrasts between parameters (e.g. `[0, 1, -1]`). Now, if we plug in this mathematical definition of design variance in the formula of the standard error of a given contrast, we get:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{SE}_{\\mathbf{c}\\hat{\\beta}} = \\sqrt{\\mathrm{noise} \\cdot \\mathrm{design\\ variance}} = \\sqrt{\\hat{\\sigma}^{2}\\mathbf{c}(\\mathbf{X}^{T}\\mathbf{X})^{-1}\\mathbf{c}^{T}}\n",
"\\end{align}\n",
"\n",
"Now, we can write out the entire formula for the *t*-statistic:\n",
"\n",
"\\begin{align}\n",
"t_{\\mathbf{c}\\hat{\\beta}} = \\frac{\\mathbf{c}\\hat{\\beta}}{\\sqrt{\\hat{\\sigma}^{2}\\mathbf{c}(X'X)^{-1}\\mathbf{c}'}} = \\frac{\\mathrm{effect}}{\\sqrt{\\mathrm{noise} \\cdot \\mathrm{design\\ variance}}}\n",
"\\end{align}\n",
"\n",
"---\n",
"\\* Actually, design variance does not depend on the \"variance\" and \"covariance\", but on the sums-of-squares of each predictor $j$ ($\\mathrm{SS}_{X_{j}}$) and sums-of-squares cross-products ($\\mathrm{SS}_{X_{j}, X_{k}}$), respectively. These are just the variance and covariance terms, but without dividing by $N - 1$! We used the terms variance and covariance here because they are more intuitive."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Summary: effects, noise, and design variance\n",
"\n",
"Alright, that's a lot of math. Sorry about that. But the above formula nicely illustrates that, to obtain large effects (i.e. *t*-values), you need three things:\n",
"\n",
"1. A large response/effect (i.e. $\\beta$)\n",
"2. An efficient design or, in other words, low design variance (i.e. high variance, low covariance: $\\frac{1}{c(X^{T}X)^{-1}c'}$)\n",
"3. Low noise/unexplained variance (i.e. low $\\mathrm{SSE}\\ /\\ \\mathrm{DF}$)\n",
"\n",
"This week, we'll discuss how to optimize (2): the efficiency from the design. Next week, we'll discuss how to minimize (3): noise (unexplained variance).\n",
"\n",
"If you remember these three components and how they conceptually relate to the effect we want to measure (*t*-values), you understand the most important aspect of experimental design in fMRI! In the rest of the tutorial, we're going to show you **why** you want high variance and low covariance in your design ($X$) and **how** to achieve this by designing your experiment in a specific way."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (0 points)\n",
" \n",
"In the previous section, you've seen a lot of math and definitions of (statistical) concepts. Especially the part on the inverses (e.g. efficiency is the inverse of design-variance, and vice versa). \n",
"\n",
"It is important to understand how all the concepts (signal/beta, noise/SSE, design variance, efficiency) relate to each other and to the thing we're after: strong effects (high *t*-values)!\n",
"\n",
"Therefore, we captured the *conceptual* formula in a function below named conceptual_tvalue_calculator, which takes three inputs — signal, noise, and design variance — and outputs the effect (*t*-value) and design efficiency. \n",
"\n",
"In the cell below, we call the function with some particular values for the three input-arguments (SIGNAL, NOISE, DESIGN_VARIANCE). For this (ungraded) ToDo, try to change these input parameters and try to understand how changing the inputs changes the outputs!\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def conceptual_tvalue_calculator(signal, noise, design_variance):\n",
" \"\"\" Calculate the effect (t-value) from the signal, noise, and design variance components.\n",
" \n",
" Parameters\n",
" ----------\n",
" signal : int/float\n",
" noise : int/float\n",
" design_variance : int/float\n",
" \n",
" Returns\n",
" -------\n",
" effect : float\n",
" efficiency : float\n",
" \"\"\"\n",
" efficiency = 1 / design_variance\n",
" effect = signal / (noise * design_variance)\n",
" return effect, efficiency"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Change the capitalized variables to see what effect it has on the t-value and efficiency\n",
"SIGNAL = 0.5\n",
"NOISE = 2.8\n",
"DESIGN_VARIANCE = 0.02\n",
"\n",
"effect, efficiency = conceptual_tvalue_calculator(signal=SIGNAL, noise=NOISE, design_variance=DESIGN_VARIANCE)\n",
"\n",
"print(\"Effect ('t-value'): %.3f\" % effect)\n",
"print(\"Efficiency: %.3f\" % efficiency)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (1 point): Researchers do not need to acquire (fMRI) data ($\\mathbf{y}$) to calculate the efficiency of their design ($\\mathbf{X}$). Why? \n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "168a916837e645ecf01aaa6d12183813",
"grade": true,
"grade_id": "cell-dff599ab71330211",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### How to calculate design variance and efficiency in Python\n",
"As discussed in the previous section, the formula for design variance (and efficiency) is often expressed using linear algebra notation:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{design\\ variance} = \\mathbf{c}(\\mathbf{X}^{T}\\mathbf{X})^{-1}\\mathbf{c}^{T}\n",
"\\end{align}\n",
"\n",
"You have seen the $(\\mathbf{X}^{T}\\mathbf{X})$ earlier when we discussed the solution for finding the least squares solution. Now, design variance is calculated by pre and postmultiplying this term with the (transpose of the) contrast vector (denoted with `c` and `c.T`). As such, so the full design variance calculation can be implemented in python as follows:\n",
"\n",
"```python\n",
"design_var = c @ inv(X.T @ X) @ c.T\n",
"```\n",
"\n",
"Given that efficiency is the inverse of design variance:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{efficiency} = \\frac{1}{\\mathbf{c}(\\mathbf{X}^{T}\\mathbf{X})^{-1}\\mathbf{c}^{T}}\n",
"\\end{align}\n",
"\n",
"... we can calculate efficiency as:\n",
"\n",
"```python\n",
"efficiency = 1.0 / c @ inv(X.T @ X) @ c.T\n",
"```\n",
"\n",
"You'll have to implement this yourself in a later ToDo! But first, let's go into more detail *why* high variance and low covariance are important to get large effects!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The effect of predictor variance on design variance/efficiency\n",
"As explained in the previous section, design variance depends on (1) predictor variance and (2) predictor covariance. In this section, we'll focus on predictor variance. In the next section, we'll focus on predictor covariance.\n",
"\n",
"As you probably know, *variance* is a statistical property of a random variable that describes the average squared deviation from the variable's mean. Formally, for any variable $x$ with mean $\\bar{x}$ and length $N$, its sample variance is defined as:\n",
"\n",
"\\begin{align}\n",
"\\mathbf{var}[x] = \\frac{1}{N - 1}\\sum_{i=1}^{N}(x - \\bar{x})^{2}\n",
"\\end{align}\n",
"\n",
"So, the more values of a variable deviate from its mean on average, the more variance it has.\n",
"\n",
"To demonstrate the effect of predictor variance on design variance/efficiency, we will focus (for simplicity) on non-time series designs that have just a single condition and thus a single predictor (apart from the intercept). In these examples, we'll focus on why high variance is important. \n",
"\n",
"### An example of the effect of (high) design variance\n",
"To start, we want to show you — conceptually — why it is important to have a lot of variance in your predictors for a low standard error of your beta, and thus high t-values. We're going to show you an example of 'regular' linear regression (so no time-series signal, but the example holds for MRI data).\n",
"\n",
"Suppose we want to investigate the effect of someone's IQ on their income ($\\mathbf{X} = IQ$, $\\mathbf{y} = income$). We've gathered some data, which we'll as usual represent as an independent variable ($\\mathbf{X}$) and a dependent variable ($\\mathbf{y}$). We'll also run the regression analysis and calculate the beta-parameters, MSE and *t*-value (corresponding to the IQ-parameter \"against baseline\")."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"from niedu.utils.nii import calculate_stats_for_iq_income_dataset\n",
"\n",
"# Load the data\n",
"iq_income_data = np.load('iq_variance_example.npz')\n",
"X_lowvar = iq_income_data['X_lv']\n",
"y_lowvar = iq_income_data['y_lv']\n",
"print(\"Shape X: %s\" % (X_lowvar.shape,))\n",
"print(\"Shape y: %s\" % (y_lowvar.shape,))\n",
"\n",
"beta_lv, mse_lv, tval_lv = calculate_stats_for_iq_income_dataset(iq_income_data, which='lowvar')\n",
"\n",
"plt.figure(figsize=(7, 7))\n",
"plt.title(\"Relation between IQ (X) and income (y)\", fontsize=15)\n",
"plt.scatter(X_lowvar[:, 1], y_lowvar, c='tab:blue')\n",
"plt.ylabel('Income (x 1000 euro)', fontsize=20)\n",
"plt.xlabel('IQ', fontsize=20)\n",
"plt.plot(\n",
" (116, 128), \n",
" (116 * beta_lv[1] + beta_lv[0], 128 * beta_lv[1] + beta_lv[0]), c='tab:orange', lw=3\n",
")\n",
"plt.text(118, 66, r'$\\hat{\\beta}_{IQ} = %.3f$' % beta_lv[1], fontsize=15)\n",
"plt.text(118, 65, 'MSE = %.3f' % mse_lv, fontsize=15)\n",
"plt.grid()\n",
"plt.xlim(116, 128)\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"This is pretty awesome data! On average, our prediction is on average less than 1 point off (i.e., $\\mathrm{MSE} < 1$)! But you might also have noticed that the *range* of values for $X$ (i.e., IQ) is quite limited: we only measured people with IQs between about 118 and 127. This is quite a narrow range — in other words: little variance — knowing that IQ varies according to a normal distribution with mean 100 and standard deviation 15. In other words, we have a pretty good model, but it is only based on a specific range of the IQ-variable. \n",
"\n",
"Think about it this way: this model captures the relationship between IQ and income, but only for relatively high-intelligence people. Sure, you can extrapolate to IQ-values like 80 and 90, but this extrapolation is quite uncertain because you've never even measured someone with that IQ-value! \n",
"\n",
"So, for comparison, let's a similar dataset with IQ and income, but this time with a much larger range of the IQ-variable. We'll plot the two datasets (the low-variance and high-variance data) next to each other. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"X_highvar = iq_income_data['X_hv']\n",
"y_highvar = iq_income_data['y_hv']\n",
"\n",
"x_lim = (65, 130)\n",
"y_lim = (0, 80)\n",
"\n",
"plt.figure(figsize=(15, 7))\n",
"plt.subplot(1, 2, 1)\n",
"plt.title(\"Low-variance data (zoomed out)\", fontsize=20)\n",
"plt.scatter(X_lowvar[:, 1], y_lowvar, c='tab:blue')\n",
"plt.ylabel('Income (x 1000 euro)', fontsize=20)\n",
"plt.xlabel('IQ', fontsize=20)\n",
"plt.xlim(x_lim)\n",
"plt.ylim(y_lim)\n",
"plt.plot(x_lim, (x_lim[0] * beta_lv[1] + beta_lv[0], x_lim[1] * beta_lv[1] + beta_lv[0]), c='tab:orange', lw=3)\n",
"plt.text(70, 70, r'$\\hat{\\beta}_{IQ} = %.3f$' % beta_lv[1], fontsize=20)\n",
"plt.text(70, 65, 'MSE = %.3f' % mse_lv, fontsize=20)\n",
"plt.grid()\n",
"\n",
"# Now, do the same calculations for the highvar data\n",
"beta_hv, mse_hv, tval_hv = calculate_stats_for_iq_income_dataset(iq_income_data, which='highvar')\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"plt.title(\"High-variance data\", fontsize=20)\n",
"plt.scatter(X_highvar[:, 1], y_highvar, c='tab:blue')\n",
"plt.xlim(x_lim)\n",
"plt.ylim(y_lim)\n",
"plt.xlabel('IQ', fontsize=20)\n",
"plt.plot(x_lim, (x_lim[0] * beta_hv[1] + beta_hv[0], x_lim[1] * beta_hv[1] + beta_hv[0]), c='tab:orange', lw=3)\n",
"plt.text(70, 70, r'$\\hat{\\beta}_{IQ} = %.3f$' % beta_hv[1], fontsize=20)\n",
"plt.text(70, 65, 'MSE = %.3f' % mse_hv, fontsize=20)\n",
"plt.tight_layout()\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see from the plots of the two datasets side-by-side, both the low-variance (left) and the high-variance plot (right) capture approximately the model: for each increase in an IQ-point, people earn about 1000 (low-variance model) / 959 (high-variance model) euro extra (these are reflected by the beta-parameters!).\n",
"\n",
"But, you also see that the MSE for the high-variance model is *much* higher, which is also evident from the residuals (distance of the red points from the blue line)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"mse_ratio = mse_hv / mse_lv\n",
"print(\"The MSE of the high-variance data is %.3f times larger than the low-variance data!\" % mse_ratio)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Given these statistics, you might guess that the t-value of the IQ-parameter in the high-variance model would be way lower than the same parameter in the low-variance model, right? Well, let's check it out:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# We calcalated the t-values earlier with the calculate_stats_for_iq_income_dataset function\n",
"print(\"T-value low-variance model: %.3f\" % tval_lv)\n",
"print(\"T-value high-variance model: %.3f\" % tval_hv)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"You probably by now understand what's the culprit: the design-variance! Given that the effect ($\\hat{\\beta}_{IQ}$) is about the same for the two models and the MSE is higher for the high-variance model, the logical conclusion is that *the design-variance of the high-variance model must be waaaaay lower*. "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" ToDo (2 points): Use the two design-matrices (X_highvar and X_lowvar) to calculate the design-variances of both the low-variance and the high-variance dataset for the \"contrast against baseline\", i.e., $H_{0}: \\beta_{IQ} = 0$ and $H_{a}: \\beta_{IQ} \\neq 0$. Then, divide the design-variance of the low-variance dataset by the high-variance dataset and store this in the variable desvar_ratio (this indicates how much higher the design-variance of the low-variance dataset is compared to the high-variance dataset). Make sure to use an appropriate contrast-vector!\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "e0c565e8cda72ba95f4ffb8bb2246bcd",
"grade": false,
"grade_id": "cell-e112d5d413656e9e",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "edf400930d2ef0cd680a61961978400e",
"grade": true,
"grade_id": "cell-950489a9e3d05ff4",
"locked": true,
"points": 2,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_3 import test_lowvar_vs_highvar_iq_design\n",
"test_lowvar_vs_highvar_iq_design(X_lowvar, X_highvar, desvar_ratio)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (1 point): Design efficiency (and design-variance) is a metric without a clear unit of measurement; herefore, efficiency (and design variance) should always be interpreted in relative terms. To show this, we are going to look at the weight-height example from last week, in which we used weight as a predictor for height. Now, we're going to rescale the predictor ('weight') such that it represents weight in grams instead of *kilos* (as was originally the case).\n",
"\n",
"Calculate efficiency for both the weight-in-kilos data (X_kilos) and the weight-in-grams data (X_grams). Store the efficiency for the weight-in-kilos data in a variable named efficiency_kilos and the efficiency for the weight-in-grams data in a variable named efficiency_grams. \n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "c260835835de65185669fb702935865e",
"grade": false,
"grade_id": "cell-df2a64e4960d3034",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"with np.load('weight_height_data.npz') as data:\n",
" X_kilos = data['X']\n",
" X_grams = X_kilos * 1000\n",
" \n",
" # We'll stack an intercept for you!\n",
" intercept = np.ones((X_kilos.size, 1))\n",
" X_kilos = np.hstack((intercept, X_kilos))\n",
" X_grams = np.hstack((intercept, X_grams))\n",
"\n",
"# Start your ToDo here\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "47851815fa22c83112891f58566ab081",
"grade": true,
"grade_id": "cell-352a2d12c07d5cd8",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_3 import test_design_variance_scaling\n",
"test_design_variance_scaling(X_kilos, X_grams, efficiency_kilos, efficiency_grams)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (1 point): If you've done the above ToDo correctly, you should see that (everything else being equal) the design with weight in grams is a 1,000,000 times more efficient than the design with weight in kilos.\n",
"\n",
"Why is the efficiency a million times higher and not 1000 times higher (as the scale-difference would suggest)?\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "3f0e9b7b59e067dcc1d046c71b1e4f96",
"grade": true,
"grade_id": "cell-c361c3d3db5b6a4b",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## The effect of predictor covariance on design variance/efficiency\n",
"\n",
"### Multicollinearity\n",
"In the previous section, we discussed the influence of predictor variance - $\\mathrm{var}[\\mathbf{X}_{j}]$ - on the design-variance term, showing that high variance leads to (relatively) low design variance (and thus high efficiency). \n",
"\n",
"We know, however, that design variance *also* depends on the *covariance* between predictors - $\\mathrm{cov}[\\mathbf{X}_{j}, \\mathbf{X}_{k}]$. This \"covariance between predictors\" is also known as **multicollinearity**. \n",
"\n",
"Specifically, the **higher** the covariance (multicollinearity), the **lower** the design efficiency (the worse our design is). Conceptually, you can think of high covariance between predictors as causing *uncertainty* of the estimation of your beta-estimates: if your predictors are correlated, the GLM \"doesn't know\" what (de)activation it should assign to which predictor. This uncertainty due to correlated predictors is reflected in a (relatively) higher design variance term.\n",
"\n",
"Anyway, let's look at some (simulated) data. This time (unlike the variance-example), we're going to look at fMRI timeseries data. We'll simulate a design with two predictors, we'll calculate the correlation between the two predictors, and the efficiency of the design for the difference contrast between the predictors (`c = [0, 1, -1]`)."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def simulate_two_predictors(N=360, shift=30, TR=2):\n",
" ''' Simulates two predictors with evenly spaced trials,\n",
" shifted a given number of time-points. '''\n",
" \n",
" offset = 20\n",
" stop = 300\n",
" space = 60\n",
" pred1 = np.zeros(N)\n",
" pred1[offset:stop:space] = 1\n",
" pred2 = np.zeros(N)\n",
" pred2[(offset + shift):stop:space] = 1\n",
"\n",
" hrf = glover_hrf(tr=1, oversampling=1)\n",
" hrf /= hrf.max()\n",
" pred1 = np.convolve(pred1, hrf)[:N:int(TR)]\n",
" pred2 = np.convolve(pred2, hrf)[:N:int(TR)]\n",
" X = np.hstack((np.ones((int(N / 2), 1)), pred1[:, np.newaxis], pred2[:, np.newaxis]))\n",
" return X\n",
"\n",
"# We set the \"shift\" (distance between predictor 1 and 2 to 30 seconds)\n",
"X = simulate_two_predictors(N=350, shift=30, TR=2)\n",
"cvec = np.array([0, 1, -1])\n",
"corr = pearsonr(X[:, 1], X[:, 2])[0]\n",
"eff = 1.0 / cvec.dot(np.linalg.inv(X.T.dot(X))).dot(cvec.T)\n",
"plt.figure(figsize=(20, 5))\n",
"plt.plot(X[:, 1])\n",
"plt.plot(X[:, 2])\n",
"plt.text(150, 0.8, 'Corr predictors: %.3f' % corr, fontsize=14)\n",
"plt.text(150, 0.7, 'Efficiency: %.3f' % eff, fontsize=14)\n",
"plt.xlim(0, 175)\n",
"plt.legend(['Predictor 1', 'Predictor 2'], loc='lower right')\n",
"plt.xlabel(\"Time (volumes)\")\n",
"plt.ylabel(\"Activation (A.U.)\")\n",
"plt.title(\"Almost no collinearity\", fontsize=20)\n",
"plt.grid()\n",
"plt.show()\n",
"\n",
"print(\"Variance predictor 1: %.3f\" % np.var(X[:, 1], ddof=1))\n",
"print(\"Variance predictor 2: %.3f\" % np.var(X[:, 2], ddof=1))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see, the predictors are almost perfectly uncorrelated - $\\mathrm{corr}(\\mathbf{X}_{1}, \\mathbf{X}_{2}) \\approx 0$ - which corresponds to a design efficiency of 4.539. Remember, the absolute value of efficiency is not interpretable, but we can interpret it *relative to other designs*. As such, we can investigate how a design with more correlated predictors will change in terms of efficiency.\n",
"\n",
"To do so, we can simply \"shift\" the second predictor (blue line) to the left (i.e., the stimuli of predictor 2 follow the stimuli of predictor 1 more quickly). Let's check out what happens to the efficiency if we induce corelation this way:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# We set shift to 4 seconds (instead of 30 like before)\n",
"X2 = simulate_two_predictors(N=350, shift=2, TR=2)\n",
"corr2 = pearsonr(X2[:, 1], X2[:, 2])[0]\n",
"eff2 = 1.0 / cvec.dot(np.linalg.inv(X2.T.dot(X2))).dot(cvec.T)\n",
"plt.figure(figsize=(20, 5))\n",
"plt.plot(X2[:, 1])\n",
"plt.plot(X2[:, 2])\n",
"plt.text(150, 0.8, 'Corr predictors: %.3f' % corr2, fontsize=14)\n",
"plt.text(150, 0.7, 'Efficiency: %.3f' % eff2, fontsize=14)\n",
"plt.xlim(0, 175)\n",
"plt.legend(['Predictor 1', 'Predictor 2'], loc='lower right', frameon=False)\n",
"plt.xlabel(\"Time (volumes)\", fontsize=20)\n",
"plt.ylabel(\"Activation (A.U.)\", fontsize=20)\n",
"plt.title(\"Quite a bit of collinearity\", fontsize=25)\n",
"plt.grid()\n",
"plt.show()\n",
"\n",
"print(\"Variance predictor 1: %.3f\" % np.var(X2[:, 1], ddof=1))\n",
"print(\"Variance predictor 2: %.3f\" % np.var(X2[:, 2], ddof=1))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"# Let's calculate the reduction in efficiency\n",
"reduction_eff = ((eff - eff2) / eff) * 100\n",
"print(\"Efficiency is reduced with %.1f%% when increasing the correlation to %.3f\" % (reduction_eff, corr2))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see, increasing correlation between predictors has the effect of reducing efficiency, even if the predictor variance stays the same! Like we discussed earlier, this is because correlation between predictors reflects *ambiguity* about the \"source\" of an effect. \n",
"\n",
"To get a better intuition of this ambiguity, suppose that for the above design (with the correlated predictors), we observe the following signal (we just simulate the signal as the linear sum of the predictors + noise; sort of a \"reverse linear regression\"):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"np.random.seed(42)\n",
"\n",
"# Here we simulate a signal based on the predictors + noise\n",
"some_noise = + np.random.normal(0, 0.3, X2.shape[0])\n",
"sim_signal = X2[:, 1] * 2 + X2[:, 2] * 2 + some_noise\n",
"plt.figure(figsize=(15, 5))\n",
"plt.plot(X2[:, 1])\n",
"plt.plot(X2[:, 2])\n",
"plt.plot(sim_signal)\n",
"plt.xlim(0, 175)\n",
"plt.legend(['Predictor 1', 'Predictor 2', 'Signal'], loc='upper right', frameon=False)\n",
"plt.xlabel(\"Time (volumes)\", fontsize=20)\n",
"plt.ylabel(\"Activation (A.U.)\", fontsize=20)\n",
"plt.title(\"Simulated data + multicollinear predictors\", fontsize=25)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Now, if we calculate the beta-parameters of both predictors, we see that they both are given approximately equal \"importance\" (i.e., their beta-parameters are about equally high):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"betas = inv(X2.T @ X2) @ X2.T @ sim_signal\n",
"print(\"Betas (w/o intercept): %r\" % betas[1:])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"However, it is unclear to the GLM whether the peaks in the signal (green line) are caused by predictor 1 or predictor 2! While the betas themselves are not affected on average (i.e., there is no *bias*), this \"uncertainty\" (or \"ambiguity\") is reflected in the GLM through a relatively higher design variance term, that will subsequently lead to (relatively) lower *t*-values! "
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (1 point): Suppose that due to a mistake in your experimental paradigm, you actually present the two classes of stimuli (reflecting predictor 1 and predictor 2 in the above example) at the same time (blue and orange predictors completely overlap). As it turns out, you cannot (reliably) calculate the design variance for such a design. Explain concisely why this is the case.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "6b50e823dd143d06a21c816fa57a3f8c",
"grade": true,
"grade_id": "cell-97b5ee2f63e3d75a",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Evaluating multiple contrasts\n",
"Thus far, we only evaluated the efficiency for a *single* contrast, like one particular predictor against baseline, e.g. `contrast_vec = np.array([0, 1, 0])`. Often, though, you might be interested in *more than one contrast*. For example, you might be interested in the contrast of predictor \"A\" against baseline, predictor \"B\" against baseline, and the difference between predictor \"A\" and \"B\"\\*. We can simply extend our formula for efficiency to allow more than one contrast. For $K$ contrasts, efficiency is defined as:\n",
"\n",
"\\begin{align}\n",
"\\mathrm{efficiency} = \\frac{K}{\\sum_{k=1}^{K} \\mathbf{c}_{k}(\\mathbf{X}^{T}\\mathbf{X})^{-1}\\mathbf{c}_{k}^{T}}\n",
"\\end{align}\n",
"\n",
"This specific calculation of efficiency is also referred to as \"A optimality\". From the formula, you can see that the overall efficiency for multiple contrasts is basically (but not precisely) the \"average\" of the efficiencies for the individual contrasts. \n",
"\n",
"Let's practice the Python-implementation of overall efficiency for multiple contrasts in a short assignment (graded with hidden tests).\n",
"\n",
"---\n",
"\\* Note that evaluating different contrasts separately is not the same as doing an F-test (like we discussed in week 2)!"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (1 point):\n",
"With the data from the correlation-simulation (i.e., the variable X), calculate the efficiency for the set of the following contrasts:\n",
"\n",
"- predictor 1 against baseline\n",
"- predictor 2 against baseline\n",
"- prediction 1 - predictor 2\n",
"\n",
"You have to define the contrasts yourself.\n",
"\n",
"Store the overall efficiency in a variable named overall_eff. Hint: you probably need a for loop (or a list comprehension).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "089631530ce557ee28434f1f03c3fc29",
"grade": false,
"grade_id": "cell-c2f50d99d143b841",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here using X\n",
"X = simulate_two_predictors(N=350, shift=30, TR=2)\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "e851ed664efd9f9e8dc3e8e300656b68",
"grade": true,
"grade_id": "cell-771f92c810482a77",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_3 import test_overall_eff\n",
"test_overall_eff(X, overall_eff)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## How should we design our experiment to maximize efficiency?\n",
"Alright, thus far we talked about **why** you want high predictor variance and low predictor covariance for optimal estimation of effects (i.e., t-values). But this leaves us with the question: **how** should we design our experiment such that it has high variance and low covariance?\n",
"\n",
"The answer is (as is often the case): it depends."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Estimation vs. detection\n",
"The specific design of your experiment (how the stimuli are ordered and their timing) mainly depends on the *type of question* you're investigating with your fMRI experiment. These types of questions are usually divided into two categories within (univariate) fMRI studies:\n",
"\n",
"**1) You want to know whether different conditions activate voxel activity differently.**\n",
"\n",
"We've learned how to do this in week 2: essentially, you want to estimate just a beta-parameter (reflecting activation/deactivation) of your stimulus-regressors. This is a question about HRF-*amplitude* only. The far majority of fMRI research falls in this category (and it's the type we'll focus on in this course). It is often said that this type of research focuses on **detection** of a signal's response. For this question, designs are often based on canonical HRF-based convolution (or based on a basis set).\n",
"\n",
"**2) You want investigate how different conditions influence voxel activity not only by investigating the \"amplitude\" parameter of the HRF, but also parameters relating to other properties of the shape of the HRF (like width, lag, strenght of undershoot, etc.).**\n",
"\n",
"A small proportion of fMRI studies have this goal. Examples are studies that investigate [how the shape of the HRF changes with age](http://www.sciencedirect.com/science/article/pii/S1053811907010877) or that investigate [differences in HRF shape across clinical populations](http://www.sciencedirect.com/science/article/pii/S1053811907001371). We won't focus on this type of research in this course, but you should know that you can also investigate other parameters of the HRF in neuroimaging research! It if often said that this type of research focuses on **estimation** of the (shape of the) signal's response. Often, \"finite impulse reponse\" (FIR) models are used for these types of studies (which you might have seen in the videos).\n",
"\n",
"The far majority of the fMRI studies focus on questions about **detection**, i.e., based on analysis of the \"amplitude\" of the HRF. This is why we won't discuss the estimation approach (and associated models, like the FIR-based GLM) in the rest of this lab and the course in general. \n",
"\n",
"Now, given that we aim for detection, how should we design our experiment? Well, there are two \"main\" types of designs: event-related designs and blocked designs, which are discussed in the next section."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Event-related vs. blocked designs\n",
"As you've probably read in the book or seen in the videos, event-related and blocked designs differ in the *ordering* of the stimuli. Basically, event-related designs are designs in which the stimuli from different conditions are ordered randomly, while blocked designs are designs in which the stimuli of the same condition are grouped together in \"blocks\". Below, we visualized an example of each design side-by-side:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"np.random.seed(2)\n",
"\n",
"N = 180\n",
"dg_hrf = glover_hrf(tr=1, oversampling=1)\n",
"\n",
"blocked_pred1_onsets = list(range(10, 30)) + list(range(90, 110))\n",
"blocked_pred2_onsets = list(range(50, 70)) + list(range(130, 150))\n",
"N_stim = len(blocked_pred1_onsets)\n",
"blocked_pred1, blocked_pred2 = np.zeros(N), np.zeros(N)\n",
"blocked_pred1[blocked_pred1_onsets] = 1\n",
"blocked_pred2[blocked_pred2_onsets] = 1\n",
"\n",
"icept = np.ones((N, 1))\n",
"X_blocked = np.hstack((\n",
" icept,\n",
" np.convolve(blocked_pred1, dg_hrf)[:N, np.newaxis],\n",
" np.convolve(blocked_pred2, dg_hrf)[:N, np.newaxis]\n",
"))\n",
"\n",
"plt.figure(figsize=(20, 10))\n",
"\n",
"plt.subplot(2, 2, 1)\n",
"plt.title(\"Event onsets (BLOCKED)\", fontsize=20)\n",
"plt.xlim(0, N)\n",
"plt.axhline(0, c='tab:blue')\n",
"plt.grid()\n",
"\n",
"for onset in blocked_pred1_onsets:\n",
" plt.plot((onset, onset), (0, 1), c='tab:blue')\n",
"\n",
"for onset in blocked_pred2_onsets:\n",
" plt.plot((onset, onset), (0, 1), c='tab:orange')\n",
" \n",
"plt.subplot(2, 2, 3)\n",
"plt.xlim(0, N)\n",
"plt.title(\"Convolved predictors (BLOCKED)\", fontsize=20)\n",
"plt.ylim(-1, 2)\n",
"plt.plot(X_blocked[:, 1], c='tab:blue')\n",
"plt.plot(X_blocked[:, 2], c='tab:orange')\n",
"plt.grid()\n",
"plt.xlabel(\"Time (volumes)\", fontsize=15)\n",
"\n",
"er_stims = np.arange(N)\n",
"er_pred1_onsets = np.random.choice(er_stims, N_stim, replace=False)\n",
"er_stims_new = np.array([o for o in er_stims if o not in er_pred1_onsets])\n",
"er_pred2_onsets = np.random.choice(er_stims_new, N_stim, replace=False)\n",
"er_pred1, er_pred2 = np.zeros(N), np.zeros(N)\n",
"er_pred1[er_pred1_onsets] = 1\n",
"er_pred2[er_pred2_onsets] = 1\n",
"\n",
"plt.subplot(2, 2, 2)\n",
"plt.xlim(0, N)\n",
"plt.title(\"Event onsets (EVENT-RELATED)\", fontsize=20)\n",
"plt.axhline(0, c='tab:blue')\n",
"plt.grid()\n",
"\n",
"for onset in er_pred1_onsets:\n",
" plt.plot((onset, onset), (0, 1), c='tab:blue')\n",
"\n",
"for onset in er_pred2_onsets:\n",
" plt.plot((onset, onset), (0, 1), c='tab:orange')\n",
"\n",
"X_er = np.hstack((\n",
" icept,\n",
" np.convolve(er_pred1, dg_hrf)[:N, np.newaxis],\n",
" np.convolve(er_pred2, dg_hrf)[:N, np.newaxis]\n",
"))\n",
"\n",
"plt.subplot(2, 2, 4)\n",
"\n",
"plt.title(\"Convolved predictors (EVENT-RELATED)\", fontsize=20)\n",
"plt.ylim(-1, 2)\n",
"plt.plot(X_er[:, 1], c='tab:blue')\n",
"plt.plot(X_er[:, 2], c='tab:orange')\n",
"plt.axhline(0, ls='--', c='k')\n",
"plt.xlim(0, N)\n",
"plt.grid()\n",
"plt.xlabel(\"Time (volumes)\", fontsize=15)\n",
"\n",
"plt.tight_layout()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see in the plot above, a blocked design groups trials of the same condition together in blocks, while the event-related design is completely random in the sequence of trials. Note that designs can of course also be a \"mixture\" between blocked and event-related (e.g., largely random with some \"blocks\" in between).\n",
"\n",
"So, if we're interested in detection (i.e., the amplitude of the response), what should we choose? \n",
"Well, the answer is simple: **blocked designs**. \n",
"\n",
"This is because blocked designs simply (almost always) have lower design variance because of:\n",
"- lower covariance (\"correlation\")\n",
"- higher variance (\"spread\")\n",
"\n",
"Let's check this for the designs from the plot. First, we'll look at the predictor covariance, but because predictor correlation is often more interpretable (correlation = standardized covariance), we'll calculate that instead:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"corr_blocked = pearsonr(X_blocked[:, 1], X_blocked[:, 2])\n",
"corr_er = pearsonr(X_er[:, 1], X_er[:, 2])\n",
"print(\"Correlation blocked: %.3f. Correlation event-related: %.3f\" % (corr_blocked[0], corr_er[0]))"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (1 point):\n",
" \n",
"We've seen that predictor correlation is lower in blocked designs than in event-related designs. But what about predictor variance? Calculate predictor variance for predictor 1 (column 2) and predictor 2 (column 3) for both the blocked design (X_blocked) and the event-related design (X_er).\n",
"\n",
"Remember: (sample) variance is the summed squared deviation of values from a variable's mean divided by the number of observations minus 1, or formally:\n",
"\n",
"\\begin{align}\n",
"\\mathbf{var}[x] = \\frac{1}{N - 1}\\sum_{i=1}^{N}(x - \\bar{x})^{2}\n",
"\\end{align}\n",
"\n",
"Store the variance of the four predictors (2 predictions $\\times$ 2 designs) in the following variables:\n",
"\n",
"- blocked_pred1_var\n",
"- blocked_pred2_var\n",
"- er_pred1_var\n",
"- er_pred2_var\n",
"\n",
"Note: do **not** use the numpy function np.var for this ToDo (also because it's going to give you the wrong answer).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "8d40e86f5b2ce99bdfbe86073cd8df39",
"grade": false,
"grade_id": "cell-76fbcee083673c0f",
"locked": false,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# Implement your ToDo here\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"editable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "c38e414244d15f13c4a25f8380d07783",
"grade": true,
"grade_id": "cell-826406f083258e63",
"locked": true,
"points": 1,
"schema_version": 3,
"solution": false
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"''' Tests the above ToDo. '''\n",
"from niedu.tests.nii.week_3 import test_variance_computation \n",
"test_variance_computation(X_blocked, X_er, blocked_pred1_var, blocked_pred2_var, er_pred1_var, er_pred2_var)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToThink (1 point): One property/characteristic (or assumption) of the BOLD-response is especially important in generating high predictor variance, which becomes especially clear in blocked designs. Which property is this? Write your answer in the cell below.\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "20eb555dce484505a922d3ad2030771e",
"grade": true,
"grade_id": "cell-983c9bc2a21005f3",
"locked": false,
"points": 1,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo/ToThink (2 points)\n",
" \n",
"As you've seen in the previous ToDo, blocked designs have larger predictor variance and (everything else being equal) are more efficient. In fact, up to a certain point, the larger the blocks of trials, the more efficient the design. This may, at first sight, reflect idea in most psychological research that more trials (events) lead to more power.\n",
"\n",
"In fMRI designs, however, this is *not* the case, because at a certain point, longer blocks yield a *less* efficient design. Below, we define a function that simulates a single predictor for a blocked-design with a variable amount of trials in it (for a fixed experiment duration of 500 seconds and a TR of 1). So, for example, if we call the function with trials=10, it will create a design and predictor with a block of 10 consecutive stimuli (all lasting a second). We'll also plot the predictor after simulating the data. \n",
"\n",
"Now, suppose I would like to evaluate the contrast of that single predictor against baseline. In the text-cell below, argue why adding more trials does not necessarily mean a more efficient design, assuming some fixed length of the experiment.\n",
"\n",
"Hint: set the number of trials very high (e.g. N_TRIALS = 500) and see what happens with the predictor.
\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def simulate_single_predictor(trials, time_exp=500):\n",
"\n",
" if trials > time_exp:\n",
" raise ValueError(\"Cannot have more trials than timepoints!\")\n",
"\n",
" pred = np.zeros(time_exp)\n",
" onsets = np.arange(trials) \n",
" pred[onsets] = 1\n",
" dg = glover_hrf(tr=1, oversampling=1)\n",
" pred_conv = np.convolve(pred, dg)[:time_exp, np.newaxis]\n",
" X = np.hstack((np.ones((time_exp, 1)), pred_conv))\n",
" return X\n",
"\n",
"# We'll call the function above here:\n",
"contrast = np.array([0, 1])\n",
"\n",
"# you can change this variable to investigate the effect of increasing/decreasing the amount of trials\n",
"N_TRIALS = 1\n",
"X = simulate_single_predictor(trials=N_TRIALS)\n",
"\n",
"# ... and plot the predictor\n",
"plt.figure(figsize=(15, 5))\n",
"plt.plot(X[:, 1])\n",
"plt.xlim(0, 500)\n",
"plt.title(\"Simulated design/predictor with %i trials\" % N_TRIALS, fontsize=25)\n",
"plt.xlabel(\"Time (seconds/volumes)\", fontsize=20)\n",
"plt.ylabel(\"Activation (A.U.)\", fontsize=20)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "markdown",
"checksum": "074f770f871207eb45df46b34714e258",
"grade": true,
"grade_id": "cell-038b9c9c78668619",
"locked": false,
"points": 2,
"schema_version": 3,
"solution": true
}
},
"source": [
"YOUR ANSWER HERE"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### The \"paradox\" of efficiency\n",
"So, we've discussed blocked and event-related designs and we've come to the conclusion that blocked designs are simply more efficient than event-related designs. \"So, we should always use blocked designs?\", you may ask. \n",
"\n",
"Well, no.\n",
"\n",
"We've discussed the mathematics behind design variance, efficiency, and t-value in detail, but we shouldn't forget that ultimately **we're measuring the data from a living human beings in the MRI-scanner**, who tend to get bored, fall asleep, and otherwise not pay attention if the task they're doing is monotonous, predictable or simply uninteresting!\n",
"\n",
"Blocked designs, however, are (usually) exactly this: designs that are experienced as predictable, monotonous, and (relatively) boring! Like we said earlier, the effects we're going to measure depend on three things - effects, noise, and design efficiency - and psychological factors may strongly influence the \"effect\" part and thus affect the statistics we're interested in (i.e., t-values). In addition to psychological factors like boredom and inattention, blocked designs may also lead to unwanted effects like habituation (attenuation of the BOLD-response after repeated stimulation), which violate the assumption of the BOLD-response as being 'linear time-invariant' (LTI). In other words, the BOLD-response may stop 'behaving' like we assume it behaves when we use blocked designs.\n",
"\n",
"This is, essentially, the paradox of designing fMRI experiments: the most efficient designs are also the designs that (potentially) lead to the lowest signal or otherwise unintended effects (due to boredom, predictability, habituation, etc.).\n",
"\n",
"So, what do we do in practice? Usually, we use (semi-random) event-related designs. We lose some efficiency by using event-related designs instead of blocked designs, but we reduce the chance of psychological factors and other effects that reduce the measured signal or mess with the assumption of linear time-invariance.\n",
"\n",
"Given that we're going to use some event-related (i.e., \"random\") design, let's investigate how we can optimize this type of design."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Improving design efficiency for event-related designs using jittering\n",
"Usually, events in an experimental design are separated by short periods without any event; this is called the \"inter-stimulus interval\" (ISI; also called stimulus onset asynchrony, SOA) - the time between successive stimuli. For example, the experiment from the image below has an ISI of 8 seconds:\n",
"\n",
"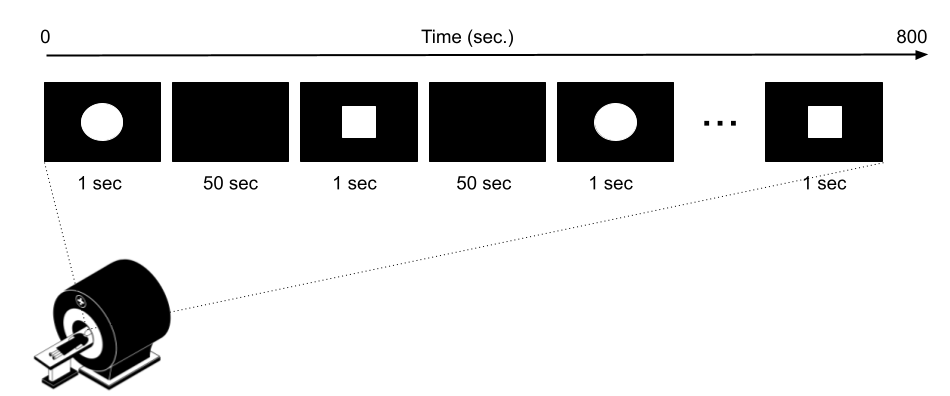\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Let's simulate some event-onsets and predictors for this experiment. We have two predictors (circles and squares). The stimuli ('events') take 1 second and the ISI is 8 seconds (like the figure above). Suppose we're interested in both contrasts against baseline (circles against baseline; squares against baseline).\n",
"\n",
"Now, let's simulate one design (with a fixed ISI), calculate efficiency and plot it:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def simulate_data_fixed_ISI(N=420):\n",
"\n",
" dg_hrf = glover_hrf(tr=1, oversampling=1)\n",
" \n",
" # Create indices in regularly spaced intervals (9 seconds, i.e. 1 sec stim + 8 ISI)\n",
" stim_onsets = np.arange(10, N - 15, 9)\n",
" stimcodes = np.repeat([1, 2], stim_onsets.size / 2) # create codes for two conditions\n",
" np.random.shuffle(stimcodes) # random shuffle\n",
" stim = np.zeros((N, 1))\n",
"\n",
" c = np.array([[0, 1, 0], [0, 0, 1]])\n",
"\n",
" # Fill stim array with codes at onsets\n",
" for i, stim_onset in enumerate(stim_onsets):\n",
" stim[stim_onset] = 1 if stimcodes[i] == 1 else 2\n",
" \n",
" stims_A = (stim == 1).astype(int)\n",
" stims_B = (stim == 2).astype(int)\n",
"\n",
" reg_A = np.convolve(stims_A.squeeze(), dg_hrf)[:N]\n",
" reg_B = np.convolve(stims_B.squeeze(), dg_hrf)[:N]\n",
" X = np.hstack((np.ones((reg_B.size, 1)), reg_A[:, np.newaxis], reg_B[:, np.newaxis]))\n",
" dvars = [(c[i, :].dot(np.linalg.inv(X.T.dot(X))).dot(c[i, :].T))\n",
" for i in range(c.shape[0])]\n",
" eff = c.shape[0] / np.sum(dvars)\n",
" return X, eff\n",
"\n",
"X, eff = simulate_data_fixed_ISI()\n",
"plt.figure(figsize=(15, 5)) \n",
"plt.title('Fixed ISI of 8 seconds (Efficiency = %.3f)' % eff, fontsize=20)\n",
"plt.plot(X[:, 1])\n",
"plt.plot(X[:, 2])\n",
"plt.legend(['Predictor A', 'Predictor B'])\n",
"plt.ylabel('Amplitude (a.u.)')\n",
"plt.xlabel('Time (TR)')\n",
"plt.xlim(0, N)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Often, though, researchers do not use a *fixed* ISI, but they vary the ISI from trial to trial. This process is called \"jittering\". Usually, the ISIs are drawn randomly from a known distribution (e.g., truncated exponential or normal distribution). Compared to using fixed ISIs, jittering may yield more efficient designs by reducing covariance and increasing predictor variance. Let's simulate another dataset, but this time with a variable ISI between 2-6 seconds (which is on average 4 seconds, but variable across trials):"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"def simulate_data_jittered_ISI(N=420):\n",
" \n",
" dg_hrf = glover_hrf(tr=1, oversampling=1)\n",
" \n",
" stim_onsets = np.arange(10, N - 15, 9)\n",
" stimcodes = np.repeat([1, 2], stim_onsets.size / 2)\n",
" np.random.shuffle(stimcodes)\n",
"\n",
" # Here, we pick some *deviations* from the standard ISI (i.e., 8),\n",
" # so possible ISIs are (8 - 2, 8 - 1, 8 - 0, 8 + 1, 8 + 2)\n",
" ISIs = np.repeat([-2, -1, 0, 1, 2], repeats=11)\n",
" np.random.shuffle(ISIs)\n",
" \n",
" stim = np.zeros((N, 1))\n",
" c = np.array([[0, 1, 0], [0, 0, 1]])\n",
"\n",
" for i, stim_onset in enumerate(stim_onsets):\n",
" # We subtract the stim-onset with -2, -1, 0, 1, or 2 (from ISIs)\n",
" # to simulate jittering\n",
" stim[stim_onset - ISIs[i]] = 1 if stimcodes[i] == 1 else 2\n",
" \n",
" stims_A = (stim == 1).astype(int)\n",
" stims_B = (stim == 2).astype(int)\n",
" reg_A = np.convolve(stims_A.squeeze(), dg_hrf)[:N]\n",
" reg_B = np.convolve(stims_B.squeeze(), dg_hrf)[:N]\n",
" X = np.hstack((np.ones((reg_B.size, 1)), reg_A[:, np.newaxis], reg_B[:, np.newaxis]))\n",
"\n",
" # Loop over the two contrasts\n",
" dvars = [(c[i, :].dot(np.linalg.inv(X.T.dot(X))).dot(c[i, :].T))\n",
" for i in range(c.shape[0])]\n",
" eff = c.shape[0] / np.sum(dvars)\n",
" return X, eff\n",
"\n",
"plt.figure(figsize=(15, 5)) \n",
"X, eff = simulate_data_jittered_ISI()\n",
"plt.title('Variable (jittered) ISI of 2-6 seconds (Efficiency = %.3f)' % eff, fontsize=20)\n",
"plt.plot(X[:, 1])\n",
"plt.plot(X[:, 2])\n",
"plt.legend(['Predictor A', 'Predictor B'])\n",
"plt.ylabel('Amplitude (a.u.)')\n",
"plt.xlabel('Time (TR)')\n",
"plt.xlim(0, N)\n",
"plt.grid()\n",
"plt.show()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"As you can see in the plot above, jittering improved design efficiency quite a bit! It is important to realize that jittering does not *always* improve design efficiency, but by \"injecting\" randomness (by selecting semi-random ISIs) it allows for *a larger variety* of designs, which also include designs that happen to be more efficient than the fixed-ISI designs. \n",
"\n",
"You'll follow up on this idea in the next ToDo."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"ToDo (3 points)\n",
" \n",
"In the previous two examples (fixed-ISI and jittered ISI examples), we saw that the fixed-ISI design was less efficient than the jittered ISI design. In general, jittering increases the number of different designs you can simulate relative to fixed-ISI designs. A great way to visualize this is to simply run the simulation of fixed-ISI and jittered-ISI designs a number of times and plot the resulting efficiencies in two separate histograms. You should see that the histogram of efficiencies from fixed-ISI designs is quite a bit narrower than the histogram of efficiencies from jittered-ISI designs (but you might also also see that some jittered-ISI designs are *less* efficient that the average fixed-ISI design).\n",
"\n",
"So, in this ToDo you will have to call the two simulation-functions (simulate_data_jittered_ISI and simulate_data_fixed_ISI) each 1000 times (use N=420, the default value) and keep track of the efficiency from both. Then, plot in *a single plot*, the histogram (using plt.hist) of the fixed-ISI efficiencies and the histogram of the jittered-ISI efficiencies. To plot two different histograms in a single plot, just call plt.hist twice (*before* calling plt.show); it will plot both histograms in the same plot.\n",
"\n",
"Also, add a legend (showing which histogram refers to which efficiencies), give a sensible label to the x-axis and y-axis (if you don't know what the axes of a histogram refer to, look it up!), and give the plot a descriptive title.\n",
"\n",
"So, in summary, you have to do the following:\n",
"- run the two functions 1000 times each\n",
"- with the resulting efficiency values (1000 for the fixed-ISI simulation function, and 1000 for the jittered-ISI simulation function), plot a histogram of the fixed-ISI efficiencies and a histogram of the jittered-ISI efficiencies in a single plot\n",
"- add a legend, labels for the axes, and a title\n",
"\n",
"Hint: the functions output two things (the design and the efficiency); you only need the efficiency (second output)\n",
"\n",
"This assignment is manually graded (no test-cell).\n",
"
"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"deletable": false,
"nbgrader": {
"cell_type": "code",
"checksum": "1add4a418a7e8f264b644c74e81bd57e",
"grade": true,
"grade_id": "cell-16a2b9d72162eca1",
"locked": false,
"points": 3,
"schema_version": 3,
"solution": true
},
"tags": [
"raises-exception",
"remove-output"
]
},
"outputs": [],
"source": [
"# implement your ToDo here\n",
"iterations = 1000\n",
"\n",
"# YOUR CODE HERE\n",
"raise NotImplementedError()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Summary: how to optimize your design for efficiency\n",
"So, in this section we discussed how to structure your experiment such that it yields a (relatively) high design efficiency, which will optimize our chance to find significant effects. How you do this depends on whether you aim for estimation (what is the shape of the HRF?) or for detection (what is the amplitude of the response?). Usually, we aim for detection; in that case, designs can be roughly grouped in two types: blocked designs an event-related designs. Purely statistically speaking, blocked designs are (almost always) more efficient, because they generally have lower covariance and higher variance than event-related designs. However, due to psychological factors and potential violations of the linear time-invariance of the BOLD-response, we often opt for event-related designs in the end. For event-related designs, we can increase our chance of finding a relatively efficient design by jittering our ISIs."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
" Tip!\n",
" Before handing in your notebooks, we recommend restarting your kernel (Kernel → Restart & Clear Ouput) and running all your cells again (manually, or by Cell → Run all). By running all your cells one by one (from \"top\" to \"bottom\" of the notebook), you may spot potential errors that are caused by accidentally overwriting your variables or running your cells out of order (e.g., defining the variable 'x' in cell 28 which you then use in cell 15).\n",
"
"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.5"
},
"toc": {
"base_numbering": 1,
"nav_menu": {},
"number_sections": true,
"sideBar": true,
"skip_h1_title": true,
"title_cell": "Table of Contents",
"title_sidebar": "Contents",
"toc_cell": false,
"toc_position": {},
"toc_section_display": true,
"toc_window_display": false
}
},
"nbformat": 4,
"nbformat_minor": 1
}